Reward is enough context : Improving Zero-Shot Generalization in Reinforcement Learning
Introduction
Reinforcement learning (RL) has achieved remarkable success in a variety of domains, from playing games to robotic control. However, one of the key challenges in RL is generalizing to unseen tasks or environments, known as zero-shot generalization. Zero-shot generalization refers to the ability of an RL agent to perform well on tasks it has never seen before, without any additional training or fine-tuning. This capability is crucial for real-world applications where agents must adapt to new scenarios without extensive retraining.
basics of rl : agent, action, environment, rewards
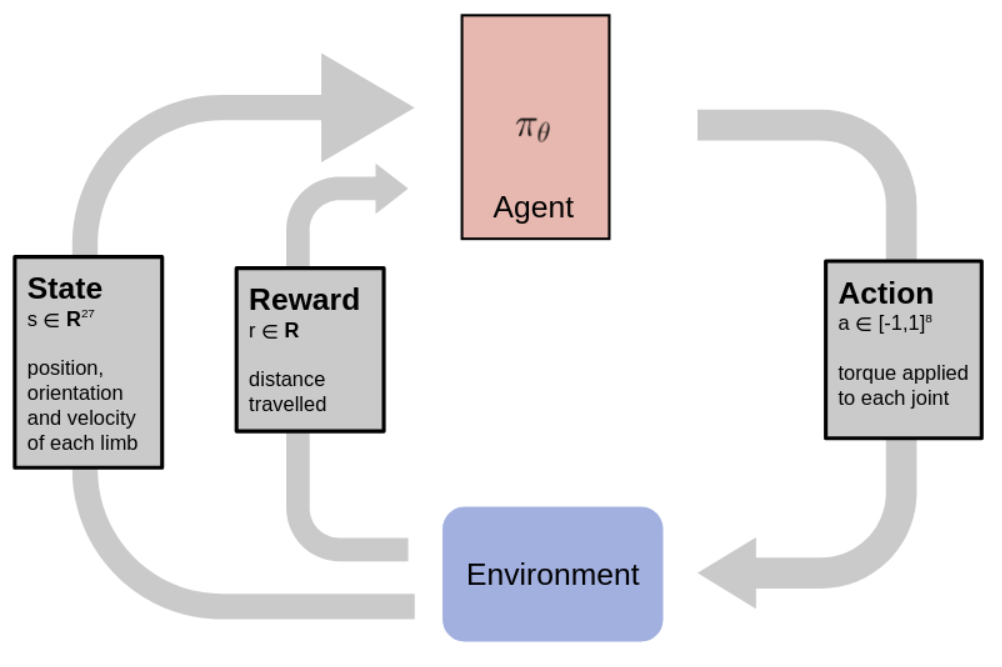 |
|---|
| Simple Reinforcement Learning schema |
example of the Ant environment in Brax : Soft actor critic learns a convincing policy in a few thousands of training steps, but fails when evaluated in an altered environment, e.g when the mass of the robot is changed.
|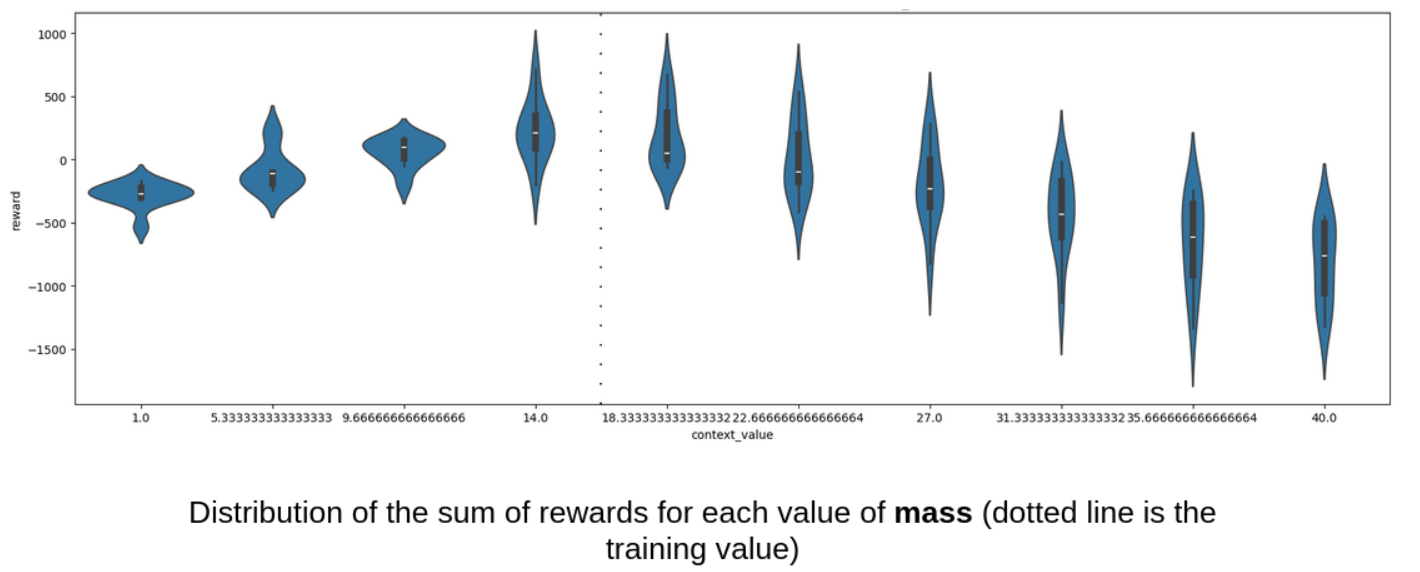 |
|
How to learn a policy that is robust to changes in dynamics ?
Learning a robust policy
contextual reinforcement learning
| |
|:–:|
| Different lenghts for cartpole |
|
|:–:|
| Different lenghts for cartpole |
Domain randomization
One approach to learning a robust policy is to train the agent in a diverse set of environments, hoping that it will learn a policy that generalizes well to unseen tasks. This approach is known as domain randomization, where the agent is trained on a distribution of environments with varying dynamics, such as mass, friction, or gravity. The idea is that by exposing the agent to a wide range of environments during training, it will learn a policy that is robust to changes in dynamics and can generalize to unseen tasks.
However, domain randomization is limited by the fact that we still learn a single policy that must work across all environments. This can lead to suboptimal performance in some environments, as the agent must compromise to perform well across the entire distribution. Lets take for example the [Gymnamsium] MountainCar environment, where an RL agent must learn to drive a car up a hill by applying force to the car.
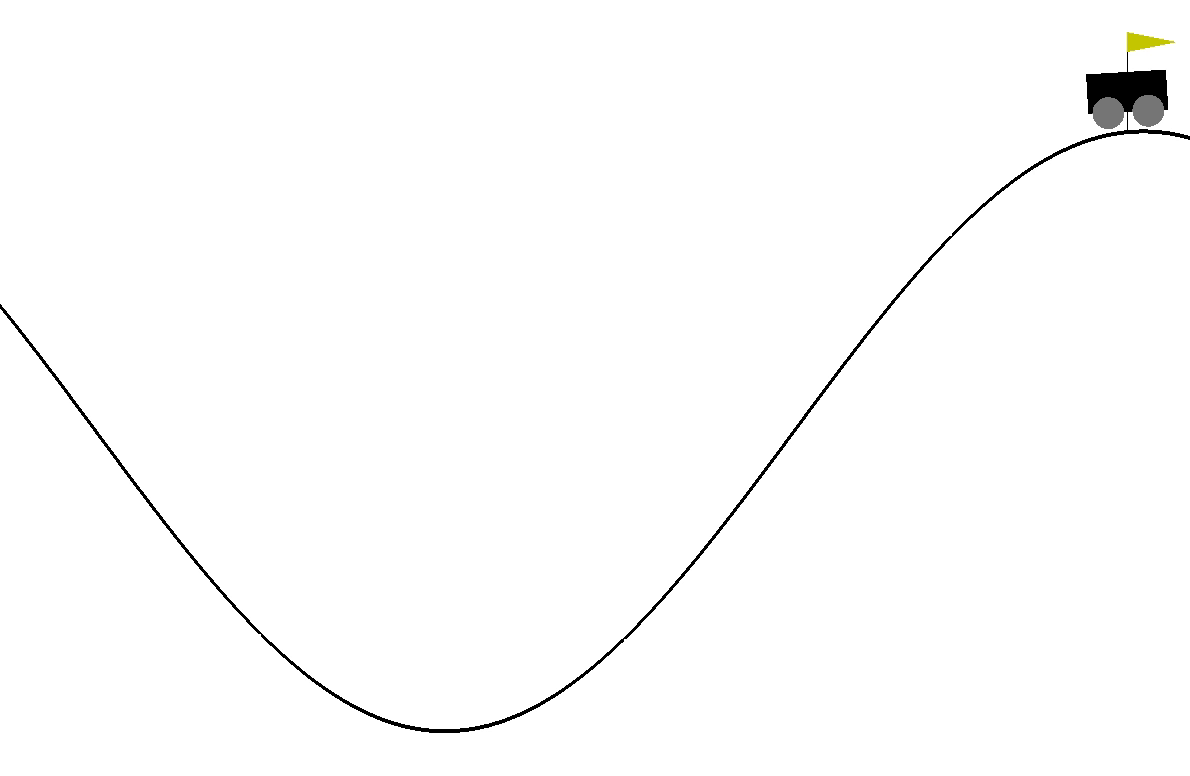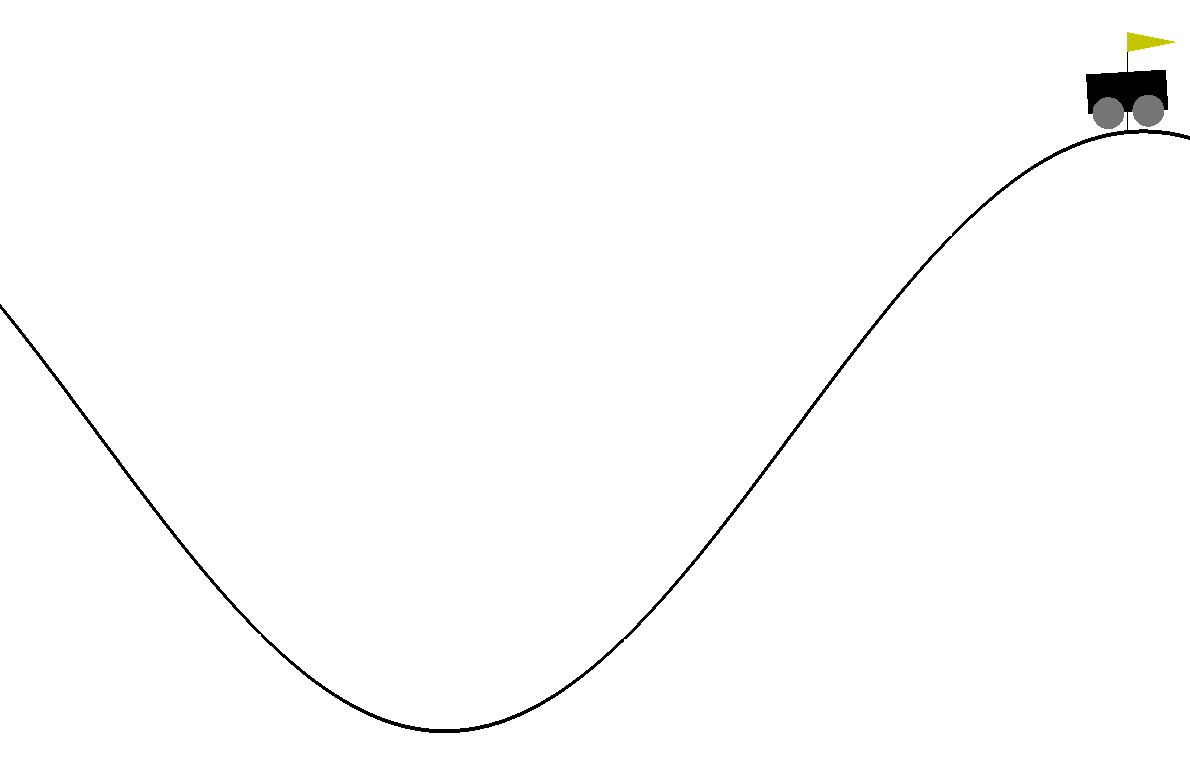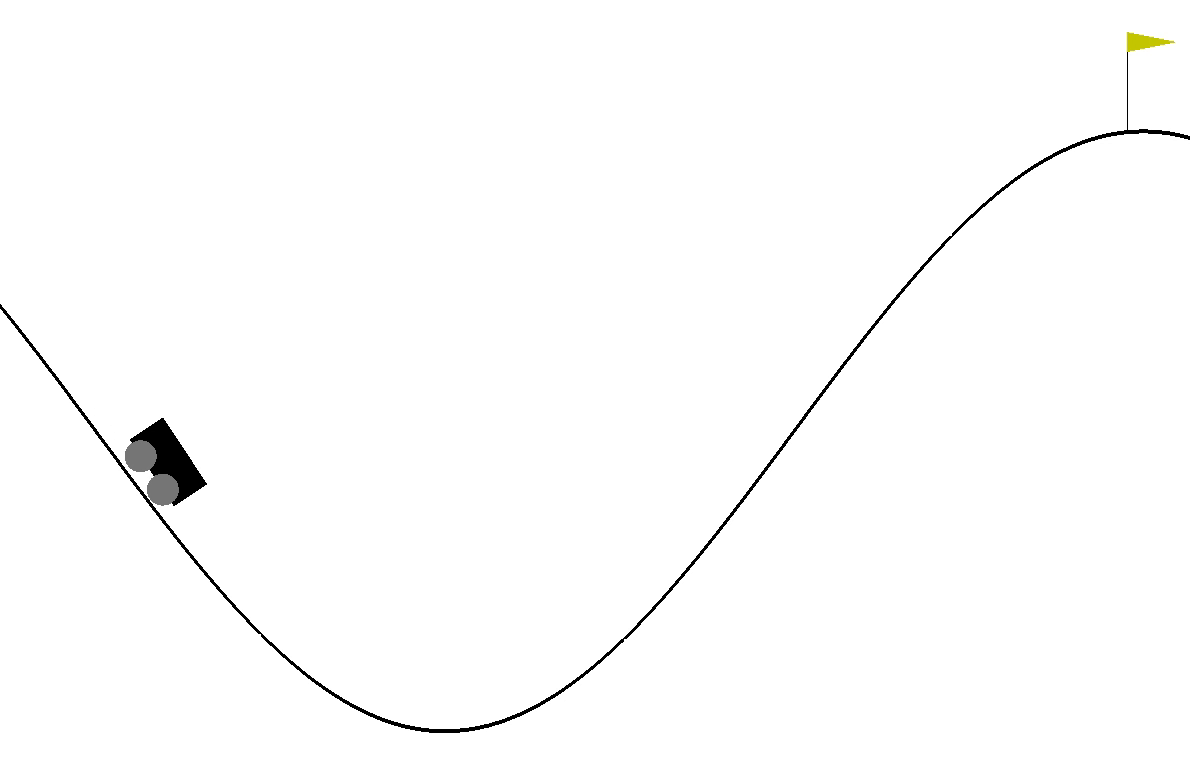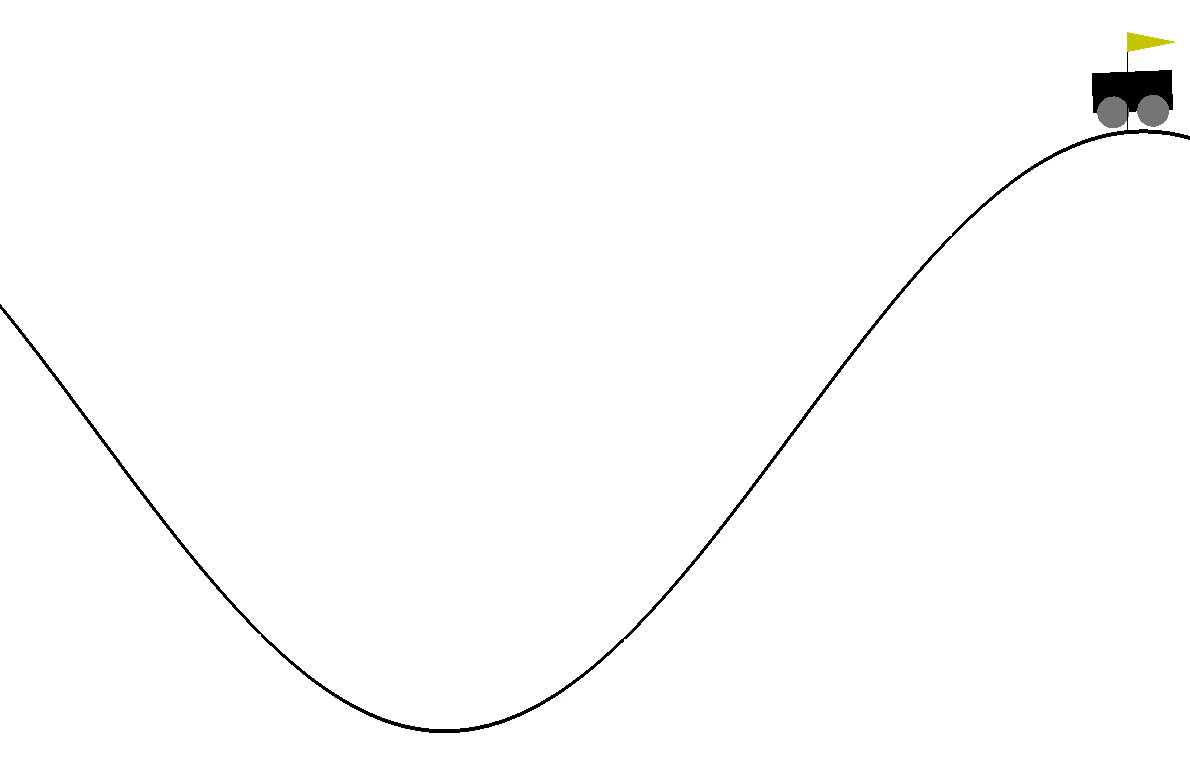 |
|---|
| mountaincar task |
In this environment, the power parameter controls the amplitude of the force applied to the car. When the agent is trained with domain randomization on a range of power values, it leads to a failing policy.
contextual reinforcement learning
|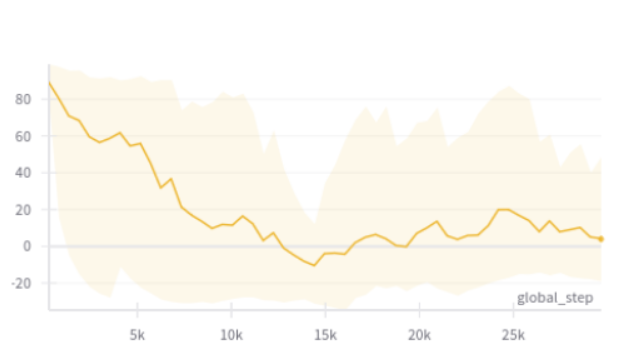 |
|:–:|
| reward curve during training |
|
|:–:|
| reward curve during training |
Providing the context directly to the agent : Explicit identification
Another approach to learning a robust policy is to provide the agent with explicit information about the task or environment it is currently facing. This approach, known as explicit identification, involves giving the agent additional context or metadata about the task, by concatenating it to the state. By providing the agent with this information, it can use it to adapt its policy to the current task and improve its performance.
In the previous example of the MountainCar environment, concatenating the power parameter to the state allows the agent to learn a policy that is robust to changes in power values during training.
However, explicit identification requires the agent to have access to the context or metadata during training and evaluation, which may not always be available in real-world scenarios.
Inferring the context from environment interactions
An alternative approach to learning a robust policy is to infer the context or task information from the agent’s interactions with the environment. This approach, known as implicit identification, involves training the agent to learn a representation of the context from the environment observations and rewards. By learning to infer the context from its interactions, the agent can adapt its policy to the current task without explicit context information.
This approach has been explored by Evans et al., 2021. In their work, they propose to encode a the environment into a low-dimensional latent space, which is then used to condition the policy.
After having collected a dataset of interactions from various contexts, a context encoder is first trained on a next-step prediction task. The context encoder is a neural network that takes the current state and action as input, as well as a list of (state, action, next state) interactions from the same context, and predicts the next observation.
This task encourages the context encoder to learn a low-dimensional representation of the context that captures the relevant information for predicting the next observation. In our example of the MountainCar environment, the embedding space is highly correlated with the power parameter.
After this first trainin step, we train the policy algorithm by appending the latent representation of the context encoder to the state at each timestep. This allows the policy to adapt to the current context and improve its performance during training.
However, this approach requires a large amount of interaction data to train the context encoder effectively, which can be challenging to collect in practice. In addition, the training is divided into two separate stages with different objectives, which might lead to learned representations that are not optimal for the policy task. We propose to join those two steps into a single training process, where the context encoder is trained jointly with the policy algorithm.
Learning context from rewards
In our approach, we propose to learn the context directly from the rewards received by the agent during training. The key idea is that the rewards provide implicit information about the task or environment the agent is currently facing, which can be used to infer the context. The context encoder is trained by backpropagating the loss of the policy algorithm through the context encoder.
In the MountainCar example, this training method leads to an higher performance of the agent during training than the predicive model of Evans et al., 2021. How well does this approach generalize to unseen context values ?