Description d'image : réseaux convolutifs et récurrents avec pytorch
L’image captioning, un champ d’études de l’analyse d’images, se penche sur la capacité des algorithmes à décrire le contenu d’une image par un texte, généralement d’une ou plusieurs phrases.
La publication Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, de Kelvin Xu et Al, propose une architecture permettant d’associer à une image une phrase descriptive. Elle est constituée d’un réseau de neurones convolutif (CNN) et d’un réseau récurrent (RNN) permettant de générer des phrases cohérentes et en rapport avec l’image. On va ici décrire brièvement le fonctionnement d’une telle architecture, et tenter de produire à notre tour des descriptions.
Partie 1 : Le CNN
Une méthode traditionnelle de machine learning pour extraire les informations d’une image est l’utilisation de réseaux de neurones, et plus particulièrement les CNN. Ils appliquent des convolutions sur la surface de l’image, permettant d’y détecter des motifs de plus ou moins haut niveau, et d’associer ces motifs aux caratéristiques de tel ou tel objet.
Lors de l’entrainement du réseau, celui-ci apprendra à la fois les caractéristiques des convolutions à appliquer, et à quel contenu associer ces motifs : visage, voiture, chat, etc …
L’architecture traditionnelle d’un CNN comprend plusieurs étapes successives de convolution/normalisation, suivies d’une couche dite dense, où tous les neurones sont connectés (située tout à droite sur le schéma):
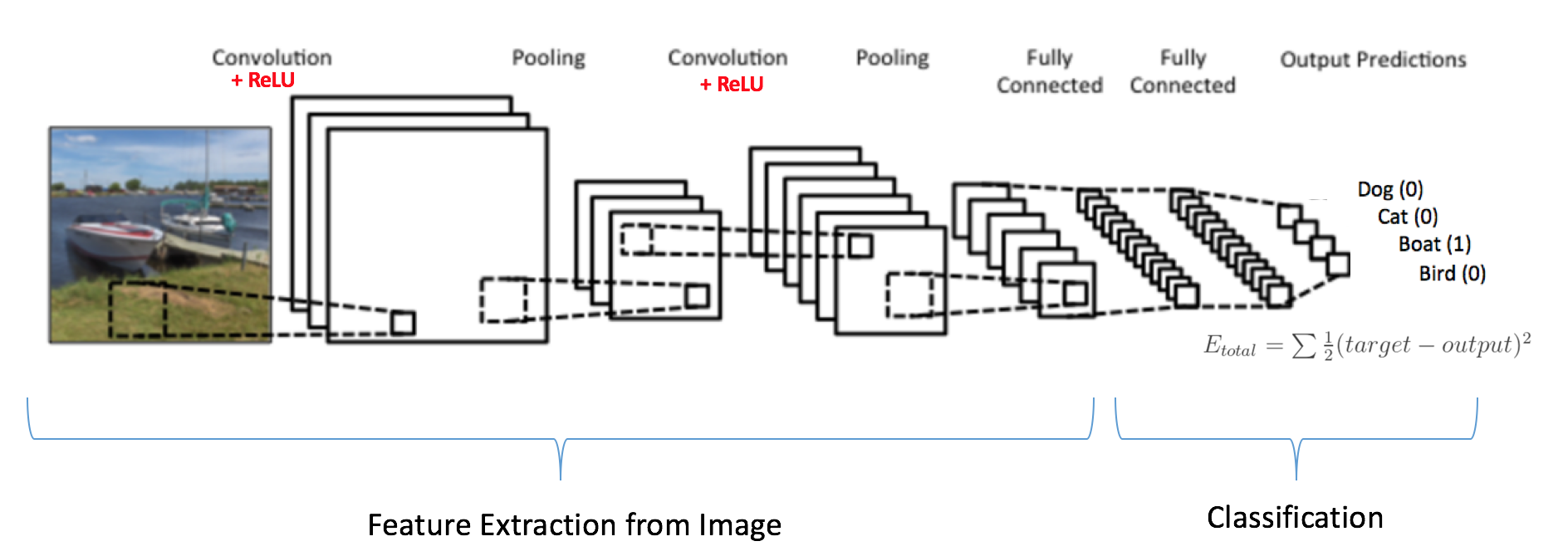 (source: Kaggle.com)
(source: Kaggle.com)
La taille de sortie de la couche dense correspond au nombre de classes que le réseau peut reconnaître.
Des CNN déja entrainés sur de grandes bases de données d’images sont disponibles sur Internet. Parmi eux, AlexNet, un CNN entrainé sur la base d’images ImageNet (1.2 millions d’images de 1000 classes différentes), et publiée en 2012, reste encore aujourd’hui un référence de modèle pré-entrainé.
Ici, nous ne voulons pas associer une image à telle ou telle catégorie, mais bien en rédiger une phrase descriptive. Même en limitant la taille maximum de la phrase, le nombre de phrases différentes possibles est beaucoup trop grand pour en associer chacune à un neurone de sortie de la couche finale.
Xu et Al montrent qu’il est toutefois possible de se servir de la capacité de représentation d’un CNN entrainé pour accomplir cette tache. Ils utilisent les couches dédiées à la convolution/normalisation, nécéssaires pour extraire les caractéristiques de l’image, mais décident d’extraire le vecteur généré à la fin de celui-ci, et de ne pas utliser la dernière couche dédiée à la classification.
Chaque image est donc transformée en un vecteur I de taille fixe :
 Ce vecteur contient un certain nombre d’informations sur l’image, même si il est ininterprétable tel quel. Xu et Al vont utiliser un autre réseau de neurones, un RNN, pour générer la phrase description à partir de ce vecteur.
Ce vecteur contient un certain nombre d’informations sur l’image, même si il est ininterprétable tel quel. Xu et Al vont utiliser un autre réseau de neurones, un RNN, pour générer la phrase description à partir de ce vecteur.
Partie 2 : Le RNN
Les RNN sont un autre type d’architecture de réseau de neurones, particulièrement utilisées dans les taches impliquant un traitement séquentiel de l’information.
Comme dans la plupart des architectures, ces réseaux prennent un vecteur en entrée, et donnent un vecteur en résultat. Cependant, ils sont construits de manière à ce que le vecteur de résultat dépende du vecteur d’entrée, mais aussi des vecteurs d’entrée recus précédemment.
Ceci fonctionne gràce au fait qu’à chaque étape du traitement, une partie des neurones du réseau conserve leur état de l’étape précédente. Cette capacité est particulièrement utile pour les taches nécéssitant une “mémorisation” des étapes au fil du temps, comme le traitement de signaux audio ou de texte.
Xu et Al s’en servent pour la génération de la description d’image : Le RNN prend ici comme état le vecteur représentatif I généré à l’étape précédente.
On met en entrée du RNN un potentiel premier mot pour la description, par exemple le mot “Un”. Le RNN génère un autre mot, par exemple “homme”, en modifiant au passage son état.
C’est ce nouvel état qui va être utilisé lors de la génération du mot suivant.
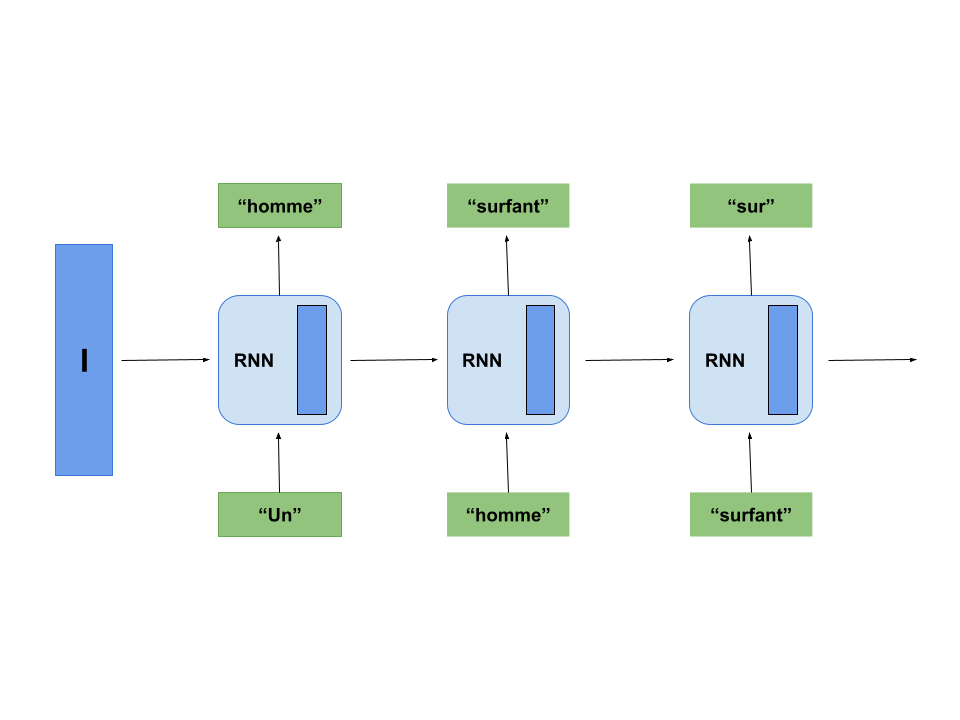
Le RNN génère donc séquentiellement une phrase, mot par mot. Intialement, sans entrainement du réseau, ces mots seront aléatoires et n’auront pas de rapport avec l’image initale. On va donc maintenant l’entrainer sur un grand nombre d’images :
Partie 3 : Les données
On va entrainer notre architecture sur la base de données COCO. Cette base de données contient des centaines de milliers d’images annotées, et est disponible au téléchargement sur https://cocodataset.org/.

On télécharge le fichier annotations_trainval2014.zip, contenant les informations de chaque image de la base à date de 2014, et on utilise la librairie pycocotools, qui contient des fonctions nous permettant de manipuler facilement ces informations.
from pycocotools.coco import COCO
coco = COCO("instances_train2014.json") #instance de classe COCO, contenant des informations relatives à chaque image
coco_caps = COCO("captions_train2014.json") #instance contenant les descriptions (plusieurs par image)
ids = list(coco.anns.keys()) #liste des identifiants des images
On peut afficher une image de notre base, ainsi que ses descriptions associées :
#import de quelques librairies pour l'affichage et la navigation
import matplotlib.pyplot as plt
import skimage.io as io
import numpy as np
%matplotlib inline
#extraction du premier id de la base
ann_id = ids[1]
#affichage de l'image et de son url fixe
img_id = coco.anns[ann_id]['image_id']
img = coco.loadImgs( img_id )[0]
url = img['coco_url']
print(url)
I = io.imread(url)
plt.imshow(I)
#affichage des descriptions
ann_ids = coco_caps.getAnnIds( img_id )
anns = coco_caps.loadAnns( ann_ids )
coco_caps.showAnns(anns)

Partie 4 : le traitement du texte
Pour permettre au RNN de traiter les phrases, on va les diviser en tokens, des unités d’informations que le réseau va pouvoir traiter une à une. Chaque mot ou symbole rencontré dans le texte de la base sera associé à un token, lui même indexé par un indice dans un dictionnaire. Nous créeons également 3 tokens spécifiques, réservés à la compréhension du texte :
<start> indiquera le début d’une description, <end> en indiquera la fin, et <unk> sera utilisé pour indiquer les éventuels mots non répertoriés dans le dictionnaire.
"""création de deux dictionnaires : word2idx et idx2word, pour passer rapidement
d'un token à son indice correpondant"""
word2idx = {'<start>': 0,
'<end>': 1,
'<unk>': 2}
idx2word = {0: '<start>',
1: '<end>',
2: '<unk>'}
idx = 3
"""Création d'un compteur comprenant tous les tokens lus dans les descriptions """
coco = COCO("annotations/captions_train2014.json")
counter = Counter()
ids = coco.anns.keys()
for i, id in enumerate(ids):
caption = str(coco.anns[id]['caption'])
tokens = nltk.tokenize.word_tokenize(caption.lower())
counter.update(tokens)
if i % 100000 == 0:
print("[%d/%d] Tokenizing captions..." % (i, len(ids)))
""" Ajout dans les dictionnaires word2idx et idx2word
de tous les mots apparaissant plus de 8 fois"""
vocab_threshold = 8
words = [word for word, cnt in counter.items() if cnt >= vocab_threshold]
for i, word in enumerate(words):
if not word in word2idx:
word2idx[word] = idx
idx2word[idx] = word
idx += 1
len(word2idx) #taille du vocabulaire : 7072 tokens
Partie 5 : Le traitement de l’image
Comme pour le texte des descriptions, l’image doit être mise sous forme vectorielle pour être traitée par le réseau. Nous la normalisons également pour la rendre plus facilement interprétable par le CNN utilisé.
On va créer notre architecture via les librairies pytorch et torchvision . Celles-ci intègrent des fonctions utiles pour le pré-traitement, comme transforms :
from torchvision import transforms
transform_train = transforms.Compose([
transforms.Resize(256), # réduction à une taille 256 * 256
transforms.ToTensor(), # conversion image->tenseur
transforms.Normalize((0.485, 0.456, 0.406), # normalisation
(0.229, 0.224, 0.225))])
Partie 6 : Préparation de l’entrainement
On a maintenant toutes les informations nécessaires pour entrainer notre réseau. Pytorch possède une classe pré-définie représentant les jeux de données, et il est possible créer une classe héritée de celle-ci pour les manipuler plus facilement. Un tutoriel détaillé disponible sur le site de Pytorch, mais en résumé, deux méthodes de la classe doivent être réecrites en fonction de notre jeu de données :
- La méthode
__getitem__, de manière à ce quedataset[i]renvoie le ième item, - La méthode
__len__, de manière à ce quelen(dataset)renvoie la taille du jeu de données.
Nous créons la classe héritée CoCoDataset :
import torch.utils.data as data
class CoCoDataset(data.Dataset):
def __init__(self, transform, mode, batch_size, vocab_threshold, vocab_file, start_word,
end_word, unk_word, annotations_file, vocab_from_file, img_folder):
self.transform = transform
self.mode = mode
self.batch_size = batch_size
self.img_folder = img_folder
if self.mode == 'train':
self.coco = COCO(annotations_file)
self.ids = list(self.coco.anns.keys())
print('Obtaining caption lengths...')
all_tokens = [nltk.tokenize.word_tokenize(str(self.coco.anns[self.ids[index]]['caption']).lower()) for index in tqdm(np.arange(len(self.ids)))]
self.caption_lengths = [len(token) for token in all_tokens]
else:
test_info = json.loads(open(annotations_file).read())
self.paths = [item['file_name'] for item in test_info['images']]
def __getitem__(self, index):
# obtention de l'image et de la description
if self.mode == 'train':
ann_id = self.ids[index]
caption = self.coco.anns[ann_id]['caption']
img_id = self.coco.anns[ann_id]['image_id']
path = self.coco.loadImgs(img_id)[0]['file_name']
# Conversion de l'image en tenseur
image = Image.open(os.path.join(self.img_folder, path)).convert('RGB')
image = self.transform(image)
# Conversion de la description en tokens, puis en ids.
tokens = nltk.tokenize.word_tokenize(str(caption).lower())
caption = []
caption.append(word2idx['<start>'])
caption.extend([word2idx[token] if token in word2idx else word2idx['<unk>'] for token in tokens])
caption.append(word2idx['<end>'])
caption = torch.Tensor(caption).long()
return image, caption
else:
path = self.paths[index]
# Conversion de l'image en tenseur
PIL_image = Image.open(os.path.join(self.img_folder, path)).convert('RGB')
orig_image = np.array(PIL_image)
image = self.transform(PIL_image)
return orig_image, image
def get_train_indices(self):
sel_length = np.random.choice(self.caption_lengths)
all_indices = np.where([self.caption_lengths[i] == sel_length for i in np.arange(len(self.caption_lengths))])[0]
indices = list(np.random.choice(all_indices, size=self.batch_size))
return indices
def __len__(self):
if self.mode == 'train':
return len(self.ids)
else:
return len(self.paths)
On crée ensuite notre instance de classe dataset :
from tqdm import tqdm
img_folder = 'cocoapi/images/train2014/'
annotations_file = 'cocoapi/annotations/captions_train2014.json'
os.chdir('/media/tidiane/D:/Dev/CV/Image_captioning')
dataset = CoCoDataset(transform=transform_train,
mode="train",
batch_size=200,
vocab_threshold=8,
vocab_file='./vocab.pkl',
start_word='<start>',
end_word='<end>',
unk_word='<unk>',
annotations_file=annotations_file,
vocab_from_file=False,
img_folder=img_folder)
num_workers=0
# Randomly sample a caption length, and sample indices with that length.
indices = dataset.get_train_indices()
# Create and assign a batch sampler to retrieve a batch with the sampled indices.
initial_sampler = data.sampler.SubsetRandomSampler(indices=indices)
# data loader for COCO dataset.
data_loader = data.DataLoader(dataset=dataset,
num_workers=num_workers,
batch_sampler=data.sampler.BatchSampler(sampler=initial_sampler,
batch_size=dataset.batch_size,
drop_last=False))
Partie 7 : L’architechture
On va maintenant pouvoir constuire notre architecture :
Pour le CNN, on se base sur le réseau resnet50, déja inclus dans la librairie torchvision. Comme indiqué précédemment, on retire la dernière couche du réseau, pour la remplacer par une couche de taille de sortie 256. Le vecteur I représentatif de chaque image aura donc cette taille.
import torch.nn as nn
import torchvision.models as models
embed_size = 256
class EncoderCNN(nn.Module):
def __init__(self, embed_size):
super(EncoderCNN, self).__init__()
resnet = models.resnet50(pretrained=True) #import de resnet50
for param in resnet.parameters():
param.requires_grad_(False)
modules = list(resnet.children())[:-1] #supression de la dernière couche
self.resnet = nn.Sequential(*modules)
self.embed = nn.Linear(resnet.fc.in_features, embed_size)
def forward(self, images):
features = self.resnet(images)
features = features.view(features.size(0), -1)
features = self.embed(features)
return features
Pour le RNN, on construit un réseau récurrent de taille d’entrée 256
hidden_size = 100
vocab_size = len(word2idx)
class DecoderRNN(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size, num_layers=1):
super( DecoderRNN , self).__init__()
self.embed_size = embed_size
self.hidden_size = hidden_size
self.vocab_size = vocab_size
self.num_layers = num_layers
self.word_embedding = nn.Embedding( self.vocab_size , self.embed_size )
self.lstm = nn.LSTM( input_size = self.embed_size ,
hidden_size = self.hidden_size,
num_layers = self.num_layers ,
batch_first = True
)
self.fc = nn.Linear( self.hidden_size , self.vocab_size )
def init_hidden( self, batch_size ):
return ( torch.zeros( self.num_layers , batch_size , self.hidden_size ).to(device),
torch.zeros( self.num_layers , batch_size , self.hidden_size ).to(device) )
def forward(self, features, captions):
captions = captions[:,:-1]
self.batch_size = features.shape[0]
self.hidden = self.init_hidden( self.batch_size )
embeds = self.word_embedding( captions )
inputs = torch.cat( ( features.unsqueeze(dim=1) , embeds ) , dim =1 )
lstm_out , self.hidden = self.lstm(inputs , self.hidden)
outputs = self.fc( lstm_out )
return outputs
def Predict(self, inputs, max_len=20):
final_output = []
batch_size = inputs.shape[0]
hidden = self.init_hidden(batch_size)
while True:
lstm_out, hidden = self.lstm(inputs, hidden)
outputs = self.fc(lstm_out)
outputs = outputs.squeeze(1)
_, max_idx = torch.max(outputs, dim=1)
final_output.append(max_idx.cpu().numpy()[0].item())
if (max_idx == 1 or len(final_output) >=20 ):
break
inputs = self.word_embedding(max_idx)
inputs = inputs.unsqueeze(1)
return final_output
Partie 8 : L’entrainement du réseau
On peut finalement entrainer notre réseau :
import math
import pickle
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
encoder = EncoderCNN( embed_size )
decoder = DecoderRNN( embed_size , hidden_size, vocab_size ,num_layers)
encoder.to(device)
images= images.to(device)
features = encoder(images)
batch_size = 200
num_layers =1
num_epochs = 4
print_every = 1 #150
save_every = 1
total_step = math.ceil( len(data_loader.dataset.caption_lengths) / data_loader.batch_sampler.batch_size )
criterion = nn.CrossEntropyLoss()
lr = 0.001
all_params = list(decoder.parameters()) + list( encoder.embed.parameters() )
optimizer = torch.optim.Adam( params = all_params , lr = lr )
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_save_path = 'models'
os.makedirs( model_save_path , exist_ok=True)
# Save the params needed to created the model :
decoder_input_params = {'embed_size' : embed_size ,
'hidden_size' : hidden_size ,
'num_layers' : num_layers,
'lr' : lr ,
'vocab_size' : vocab_size
}
with open( os.path.join(model_save_path , 'decoder_input_params_12_20_2019.pickle'), 'wb') as handle:
pickle.dump(decoder_input_params, handle, protocol=pickle.HIGHEST_PROTOCOL)
import sys
for e in range(num_epochs):
for step in range(total_step):
indices = data_loader.dataset.get_train_indices()
new_sampler = data.sampler.SubsetRandomSampler( indices )
data_loader.batch_sampler.sampler = new_sampler
images,captions = next(iter(data_loader))
images , captions = images.to(device) , captions.to(device)
encoder , decoder = encoder.to(device) , decoder.to(device)
encoder.zero_grad()
decoder.zero_grad()
features = encoder(images)
output = decoder( features , captions )
loss = criterion( output.view(-1, vocab_size) , captions.view(-1) )
loss.backward()
optimizer.step()
stat_vals = 'Epochs [%d/%d] Step [%d/%d] Loss [%.4f] ' %( e+1,num_epochs,step,total_step,loss.item() )
if step % print_every == 0 :
print(stat_vals)
sys.stdout.flush()
if e % save_every == 0:
torch.save( encoder.state_dict() , os.path.join( model_save_path , 'encoderdata_{}.pkl'.format(e+1) ) )
torch.save( decoder.state_dict() , os.path.join( model_save_path , 'decoderdata_{}.pkl'.format(e+1) ) )
Partie 9 : Test de notre architecture
cocoapi_loc=''
img_folder_test = os.path.join(cocoapi_loc, 'cocoapi/images/test2014/')
annotations_file_test = os.path.join(cocoapi_loc, 'cocoapi/annotations/image_info_test2014.json')
transform_test = transforms.Compose([
transforms.Resize(256), # smaller edge of image resized to 256
#transforms.RandomCrop(224), # get 224x224 crop from random location
transforms.RandomHorizontalFlip(), # horizontally flip image with probability=0.5
transforms.ToTensor(), # convert the PIL Image to a tensor
transforms.Normalize((0.485, 0.456, 0.406), # normalize image for pre-trained model
(0.229, 0.224, 0.225))])
dataset_test = CoCoDataset(transform=transform_test,
mode='test',
batch_size = 1,
vocab_threshold=vocab_threshold,
vocab_file=' ',
start_word=start_word,
end_word=end_word,
unk_word=unk_word,
annotations_file=annotations_file_test,
vocab_from_file=False,
img_folder=img_folder_test)
data_loader_test = data.DataLoader(dataset=dataset_test,
batch_size=dataset_test.batch_size,
shuffle=True,
num_workers=num_workers)
data_iter = iter(data_loader_test)
def get_sentences( original_img, all_predictions ):
sentence = ' '
plt.imshow(original_img.squeeze())
return sentence.join([idx2word[idx] for idx in all_predictions[1:-1] ] )
model_save_path = '/media/tidiane/D:/Dev/CV/Image_captioning/models/drive-download-20210428T070757Z-001'
os.makedirs( model_save_path , exist_ok=True)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
with open( os.path.join(model_save_path , 'decoder_input_params_12_20_2019.pickle'), 'rb') as handle:
decoder_input_params = pickle.load(handle)
embed_size = decoder_input_params['embed_size']
hidden_size= decoder_input_params['hidden_size']
vocab_size = decoder_input_params['vocab_size']
num_layers = decoder_input_params['num_layers']
encoder = EncoderCNN( embed_size )
encoder.load_state_dict( torch.load( os.path.join( model_save_path , 'encoderdata_{}.pkl'.format(4) ) ,map_location=torch.device('cpu')) )
decoder = DecoderRNN( embed_size , hidden_size , vocab_size , num_layers )
decoder.load_state_dict( torch.load( os.path.join( model_save_path , 'decoderdata_{}.pkl'.format(4) ) ,map_location=torch.device('cpu') ) )
encoder.to(device)
decoder.to(device)
encoder.eval()
decoder.eval()
original_img , processed_img = next( data_iter )
features = encoder(processed_img.to(device) ).unsqueeze(1)
final_output = decoder.Predict( features , max_len=20)
get_sentences(original_img, final_output)
