Un projet d'analyse d'images : retrouver une photo sur instagram à l'aide de sa description
La plupart des sites de partage d’images tirent profit d’algorithmes pour labelliser et classer rapidement les images postées. Instagram applique déja de lui mème, sur chaque photo postée par un utilisateur, des méthodes de classification d’images. Mais quand on examine ces descriptions, elles sont souvent assez vagues :
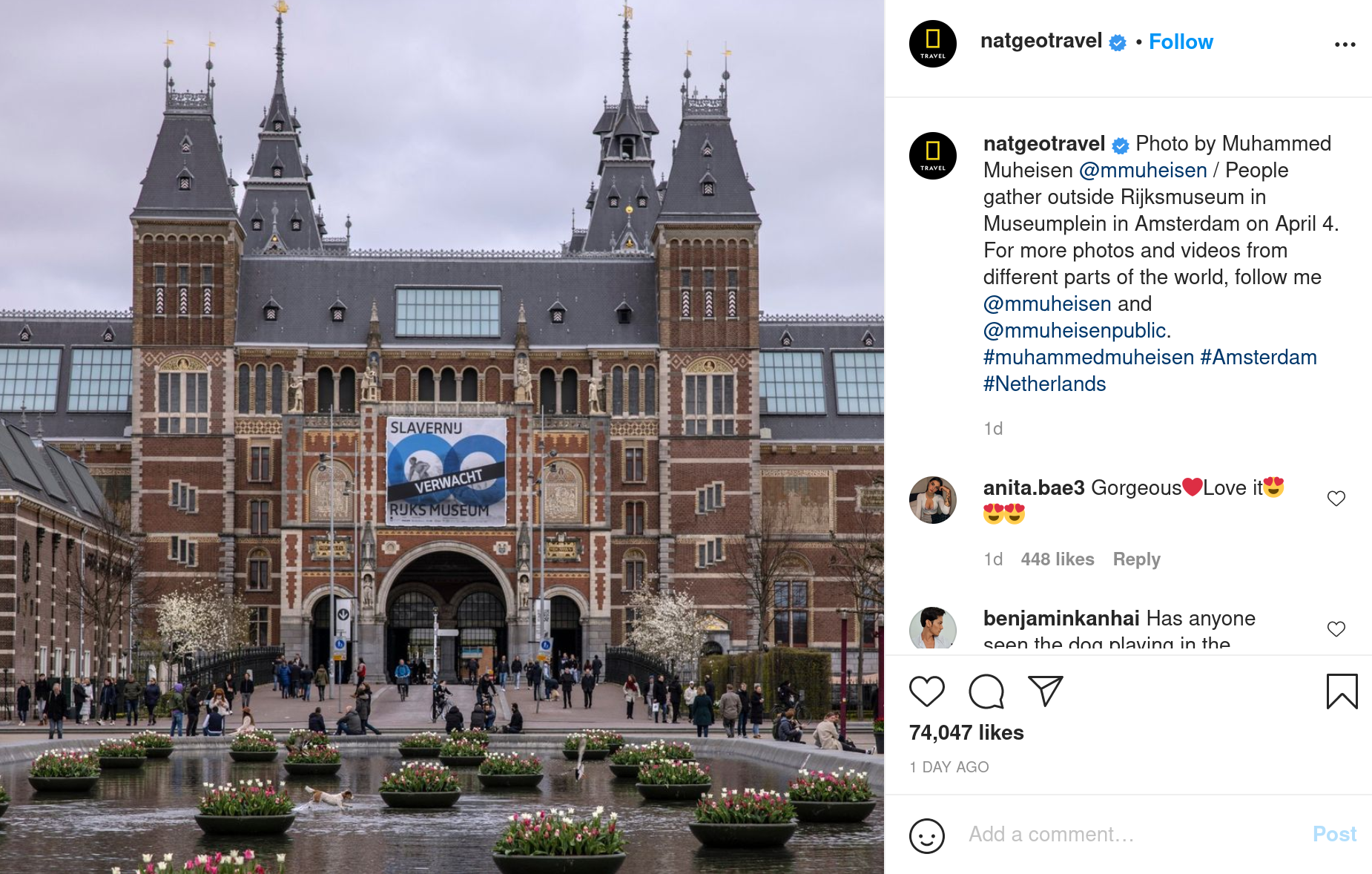

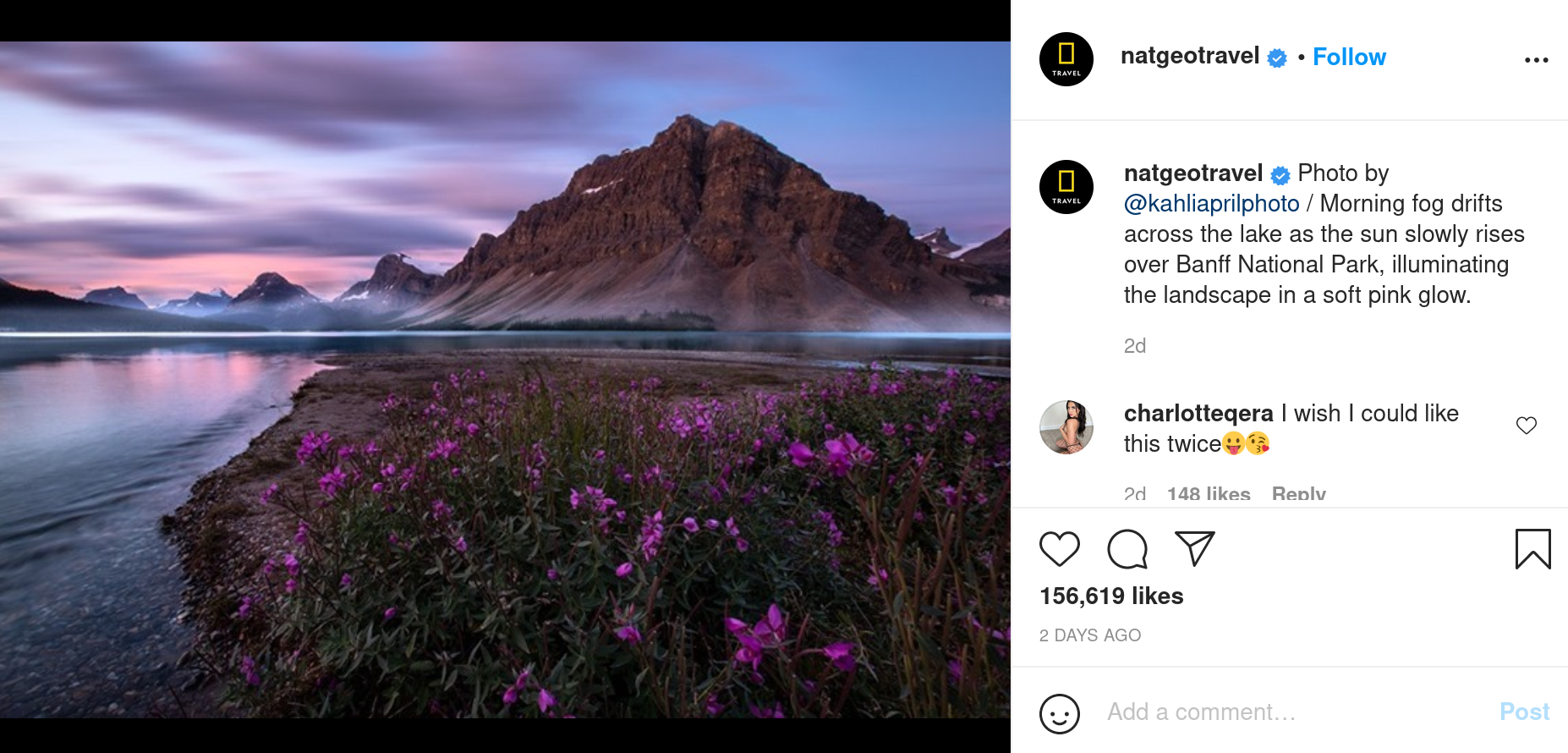

En plus de ça, Instagram ne propose pas d’outil de recherche sur les descriptions générées.
On pourrait appliquer sur ces photos d’autres méthodes d’analyse d’image, permettant de les décrire plus précisément. Ca nous permettrait de trouver facilement une image à l’aide d’une description.
On va donc ici décrire le fonctionnement d’une démo web permettant d’effectuer une recherche d’image sur un profil Instagram, à partir de descriptions que nous générerons numériquement. On utilisera python pour le côté serveur (back) et javascript pour le front.
Partie 1 : Trouver des images : Comment fouiller Instagram
On a d’abord besoin d’un ensemble d’images sur lequel effectuer notre recherche. Comme nous voulons utiliser la plateforme Instagram, on doit trouver un moyen de parcourir le site et d’en récupérer le contenu.
Instagram ne propose pas d’interface pour télécharger plusieurs photos d’un coup. A première vue, la seule solution pour se constituer une banque d’images serait donc de parcourir les profils et de les télécharger manuellement une à une.
Heureusement, des programmes permettent de ‘scraper’ Instagram, c’est-à-dire de parcourir automatiquement le site afin de récupérer les données qui nous intéressent.
Un de ces programmes, codé en python par arc298 et nommé instagram-scraper, nous permet de télécharger l’ensemble des photos d’un profil. Nous allons essayer ceci sur un profil instagram comportant un grand nombre d’images diverses : le compte NatGeoTravel de la chaîne National Geographic.
$pip install instagram-scraper
$instagram-scraper natgeotravel
Le téléchargement prend un temps assez long, environ 10 photos par seconde. Heureusement, le script possède une option permettant de récupérer uniquement les adresses url des images, avec un temps de téléchargement potentiellement plus rapide. Ces adresses nous suffiront pour accéder aux images plus tard.
$instagram-scraper natgeotravel --media-metadata --media-types none
Le temps d’exécution est effectivement bien plus court.
On stocke la liste d’urls au format json, dans un fichier nommé url_list_natgeotravel.json. Celui-ci va constituer notre base de données.
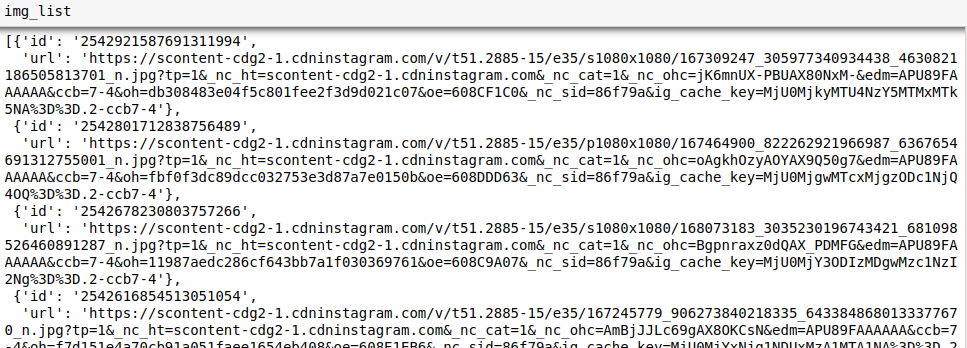 Liste des urls extraites.
Liste des urls extraites.
Partie 2 : Décrire une image : Comment analyser une image afin d’en tirer une description
Maintenant qu’on a accès aux images, on va pouvoir assigner à chacune d’entre elles une description. Une méthode traditionnelle de machine learning pour extraire les informations d’une image est l’utilisation d’un réseau de neurones, et plus particulièrement les réseaux de neurones convolutifs (CNN). Il applique des convolutions sur la surface de l’image, permettant d’y détecter des motifs de plus ou moins haut niveau, et d’associer ces motifs aux caractéristiques de tel ou tel objet.
Lors de l’entraînement du réseau, celui-ci apprendra à la fois les caractéristiques des convolutions à appliquer, et à quel contenu associer ces motifs : visage, voiture, chat, etc …

Un schéma d’architecture possible pour un CNN (source : Kdnuggets.com)
Des CNN déjà entraînés sur de grandes bases de données d’images sont disponibles sur Internet. Parmi eux, AlexNet, un CNN entrainé sur la base d’images ImageNet (1.2 millions d’images de 1000 classes différentes), et publié en 2012, reste aujourd’hui un référence de modèle pré-entrainé.

Quelques échantillons d’ImageNet (source : Devopedia )
AlexNet est disponible au téléchargement sur la page Kaggle de la librarie python Pytorch.
Il peut également être téléchargé directement depuis un script python :
import torch
model = torch.hub.load('pytorch/vision:v0.9.0', 'alexnet', pretrained=True)On peut alors récupérer l’image de notre choix via son url, avec les librairies PIL et urllib :
from PIL import Image
from urllib.request import urlopen
input_image = Image.open(urlopen("https://www.nosamis.fr/img/classic/Berger-Australien1.jpg"))
Notre image test : un berger australien.
Nous normalisons l’image et la redimensionnons, puis la mettons sous forme de tenseur, un tableau multidimensionnel utilisé comme format de données par la librairie Pytorch :
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)Nous faisons passer notre tenseur dans le modèle AlexNet :
with torch.no_grad():
output = model(input_batch)Le tenseur output contient les scores associés aux 1000 objets que peut reconnaître AlexNet. Nous appliquons la fonction softmax aux scores pour en obtenir les probabilités :
probabilities = torch.nn.functional.softmax(output[0], dim=0)Nous pouvons obtenir la liste des noms des 1000 objects reconnus par AlexNet sur le github de Pytorch :
$wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
categories[torch.argmax(probabilities)] #resultat : 'Border collie'
La probabilité la plus haute sortie par AlexNet est celle de la classe Border collie, ce qui n’est pas exactement le contenu de notre photo initiale, mais tout de même très proche compte tenu de la diversité des classes proposées par le modèle.
Cette méthode est précise sur les exemples d’images que nous lui présentons :



Malheureusement, elle nous fournit uniquement une liste d’éléments probables contenus dans l’image. Elle n’extrait pas d’actions telles que “courir”, “faire du vélo”, “allongé”, ni d’éléments contextuels de l’image tels que “sur un banc”, “au bord d’une plage”, etc …
On aimerait, pour chaque image, produire une phrase résumant son contenu, et ceci qu’elle possède des éléments identifiables individuellement ou non.
Le papier Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, de Kelvin Xu et Al propose une architecture permettant d’associer à une image une phrase descriptive. Celle-ci est constituée d’un CNN, ainsi que d’un réseau récurrent (RNN) permettant de générer des phrases cohérentes et en rapport avec l’image.
On va utiliser ici un script librement inspiré d’une implémentation de Sgrvinod, que je décris dans cet article.
$python3 imcap_sgrvinod/caption_photosearch.py --model='imcap_sgrvinod/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='imcap_sgrvinod/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5 --imglist='url_list_natgeotravel.json'--dict_path='captions_dict_natgeotravel.json'
Ce script ouvre chaque url présent dans le dictionnaire contenu dans url_list_natgeotravel.json, et écrit les descriptions produites par le modèle dans captions_dict_natgeotravel.json
 Exemple d’une description d’image générée par le script.
Exemple d’une description d’image générée par le script.
On a donc maintenant une phrase descriptive pour chaque photo du compte NatGeoTravel. On va s’en servir pour construire un moteur de recherche sur ces photos :
Partie 3 : Récupérer les meilleurs résultats : créer une API renvoyant les images les plus proches d’une description donnée
Notre but est de récupérer, pour une requête donnée, les n images dont les descriptions sont les plus proches de la requête. On va pour ça utiliser une méthode standard de recherche de texte, la méthode TF-IDF, basée sur les fréquences d’apparition des termes de la requête dans les documents recherchés.
Imaginons que nous voulons retrouver une image de personnes marchant dans la rue. Notre requète sera la chaîne de caractères suivante : “People walking down the street”. Chaque description peut contenir un nombre plus ou moins important de termes cherchés, ici en gras :
| image | sentence |
|---|---|
| img1 | A dog walking on a street |
| img2 | A young girl surfing in the ocean |
| img3 | A group of people walking down the street |
| img4 | A couple of people playing football in the park |
La méthode TF-IDF se base sur l’hypothèse que deux documents partageant un grand nombre de mots ont des chances d’être proches sémantiquement. Nous calculerons le degré de similarité entre notre requête et un texte j par le nombre de fois où un terme de la requête apparaît dans j.
Afin d’obtenir un degré de similarité entre 0 et 1, on divise (ou normalise ce nombre par le produit du nombre de mots de la requête et du texte j. Cette normalisation nous permet également en théorie de pénaliser les textes plus longs, qui de par leur taille ont statistiquement plus de chance de contenir des mots de la requête. Cependant, étant donné que les textes cherchés ont ici ont tous une taille similaire, cette normalisation a peu d’impact dans notre cas.
On utilise ici la fonction TfidfVectorizer() de la bibliothèque sklearn, qui nous permet de transformer facilement nos textes en tableaux d’occurrence de mots :
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import numpy as np
documents = [d["caption"] for d in name_data]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents)
# Convert the X as transposed matrix
X = X.T.toarray()# Create a DataFrame and set the vocabulary as the index
df = pd.DataFrame(X, index=vectorizer.get_feature_names())
On calcule les degrés de similarité entre chaque texte et la requête, puis les ajoutons à notre liste d’urls.
q = [search_string]
q_vec = vectorizer.transform(q).toarray().reshape(df.shape[0],)
sim = [] # Calculate the similarity
for i in range(len(documents)):
sim.append(np.dot(df.loc[:, i].values, q_vec) / np.linalg.norm(df.loc[:, i]) * np.linalg.norm(q_vec))
paired_scores = zip(sim,urls,txts)
On trie notre liste d’urls par ordre croissant de degré de similarité, puis on retient les 100 premiers.
sorted_scores = sorted(paired_scores, key = lambda t : t[0],reverse = True)
# Create an empty list for our results
results = [i for i in sorted_scores if i[0] > 0]
if len(results) > 100 :
results = results[:100]
Notre but est de créer une application permettant à n’importe quel utilisateur de taper sa requête, puis d’obtenir les résultats fournis par ce script. On va donc faire en sorte que le script ci-dessus se déclenche à chaque requête, en l’inscrivant à l’intérieur d’un serveur. Nous utilisons ici le framework Flask.
Pour lancer notre serveur local Flask, écrivons le script suivant, qu’on appelera api.py :
import flask
app = flask.Flask(__name__)
app.config["DEBUG"] = True
@app.route('/')
def index():
return "<h1>Le serveur marche !!</h1>"
if __name__ == '__main__':
# Threaded option to enable multiple instances for multiple user access support
app.run(threaded=True, port=5000)
On a configuré notre serveur pour qu’il nous renvoie le message html “Le serveur marche !!” lorsque nous consultons sa racine.
On lance notre script :
$python3 api.py
Notre serveur tourne maintenant en local à l’adresse http://127.0.0.1:5000/ :
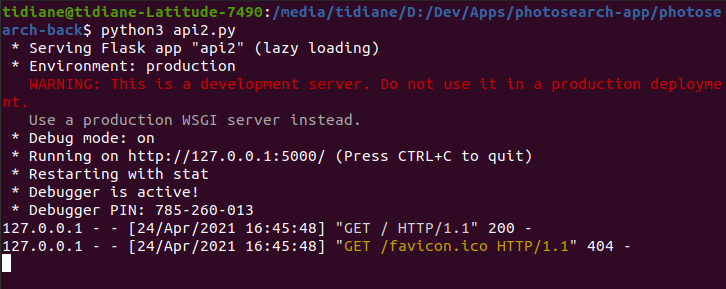
On va modifier notre script pour qu’à réception d’une requête, il nous renvoie les urls classées.
On introduit quelques librairies utiles :
import flask
from flask import request, jsonify
import json
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import numpy as np
app = flask.Flask(__name__)
app.config["DEBUG"] = True
On ouvre ensuite notre base de données :
data_file = open('photosearch_db.json', 'r')
data = json.load(data_file)
On récupère les arguments ‘name’ et ‘search_string’, qui seront respectivement l’identifiant Instagram sur lequel faire la recherche, et le texte cherché :
@app.route('/', methods=['GET'])
def api_id():
# Check if a search string and name were provided.
if ('str' in request.args) and ('name' in request.args):
search_string = str(request.args['str'])
name = str(request.args['name'])
On calcule les 100 meilleurs résultats selon la méthode TF-IDF et renvoyons les résultats :
documents = [d["caption"] for d in name_data]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents)
# Convert the X as transposed matrix
X = X.T.toarray()# Create a DataFrame and set the vocabulary as the index
df = pd.DataFrame(X, index=vectorizer.get_feature_names())
q = [search_string]
q_vec = vectorizer.transform(q).toarray().reshape(df.shape[0],)
sim = [] # Calculate the similarity
for i in range(len(documents)):
sim.append(np.dot(df.loc[:, i].values, q_vec) / np.linalg.norm(df.loc[:, i]) * np.linalg.norm(q_vec))
urls = []
txts = []
for img in name_data :
urls.append(img["url"])
txts.append(img["caption"] + img["yolo_objects"])
paired_scores = zip(sim,urls,txts)
#sorted = [x for _,x in sorted(paired_scores)]
sorted_scores = sorted(paired_scores, key = lambda t : t[0],reverse = True)
# Create an empty list for our results
results = [i for i in sorted_scores if i[0] > 0]
if len(results) > 100 :
results = results[:100]
# Use the jsonify function from Flask to convert our list of
# Python dictionaries to the JSON format.
response = jsonify(results)
response.headers.add('Access-Control-Allow-Origin', '*')
return response
On peut maintenant tester notre serveur, avec la requète “people walking on the street”, sur le compte “natgeotravel”, en accédant à l’adresse http://127.0.0.1:5000/?str=people+walking+on+street&name=natgeotravel :
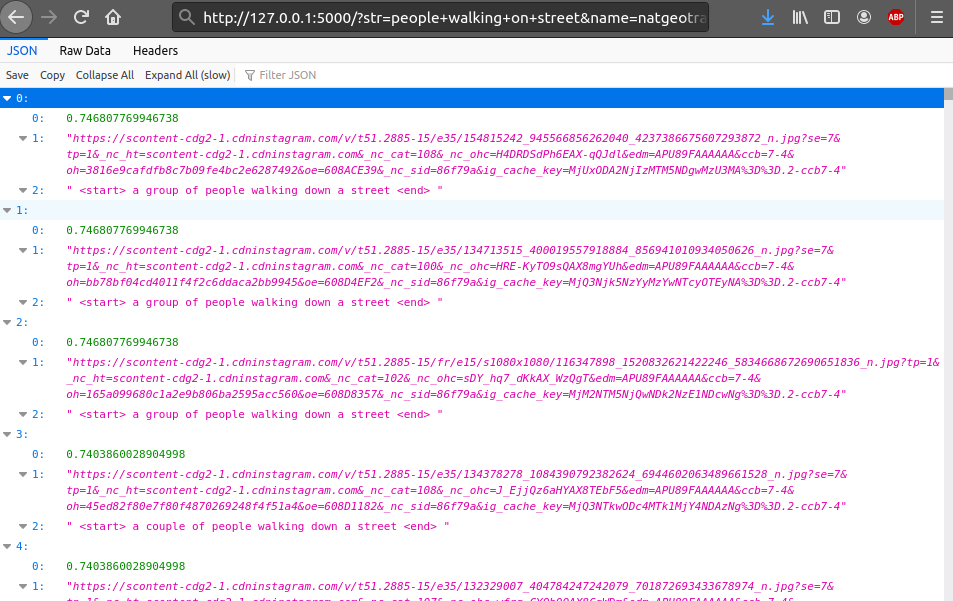
Le serveur nous renvoie bien une liste de 100 urls, ainsi que les scores de similarités et descriptions correspondantes.
Partie 4 : Afficher les résultats : créer une application interagissant avec l’API
On va maintenant construire une interface web nous permettant d’envoyer nos requêtes à l’API, et d’afficher les résultats reçus.
Plusieurs maquettes d’interface sont disponibles sur Github. On va utiliser une maquette javascript codée par lelouchB, sous le framework react.
En l’état, l’application utilise l’API d’Unsplash, une banque d’images. On va modifier le code source du fichier searchPhotos.js pour qu’elle utilise notre API.
On commence d’abord par importer axios, une librairie facilitant la gestion des requêtes http :
import React, { Fragment, useState, useEffect } from 'react';
import axios from 'axios';
On écrit ensuite nos hooks, qui définiront l’état de nos requêtes :
export default function SearchInst() {
const [data, setData] = useState([]);
const [query, setQuery] = useState('people walking on street');
const [name, setName] = useState('natgeotravel');
const [url, setUrl] = useState(
'http://127.0.0.1:5000/api/v1/search?str=home&name=natgeotravel'
);
useEffect(() => {
const fetchData = async () => {
const result = await axios(url);
setData(result.data);
};
fetchData();
},[url]);
On définit ensuite les textbox correspondant au texte et à l’identifiant utilisateur cherchés, ainsi que le bouton pour lancer la recherche :
return (
<Fragment>
<input
type="text"
value={query}
onChange={event => setQuery(event.target.value)}
/>
<input
type="texts"
value={name}
onChange={event => setName(event.target.value)}
/>
<button type="button" onClick={() => setUrl(`https://photosearch-back.herokuapp.com/api/v1/search?str=${query}&name=${name}`)}>
Search
</button>
Et on renvoie enfin notre liste d’images.
<div className="card-list">
{data.map((pic) => (
<div className="card" key={data.id}>
<img
className="card--image"
src={pic[1]}
alt={pic[4]}
title={pic[2]}
width="50%"
height="50%"
></img>
</div>
))}
</div>
</Fragment>
);
}
On peut maintenant lancer notre application react à partir du dossier racine de l’application :
$yarn start
Notre application est maintenant disponible à l’adresse affichée. Elle affiche bien les images envoyées par notre API :
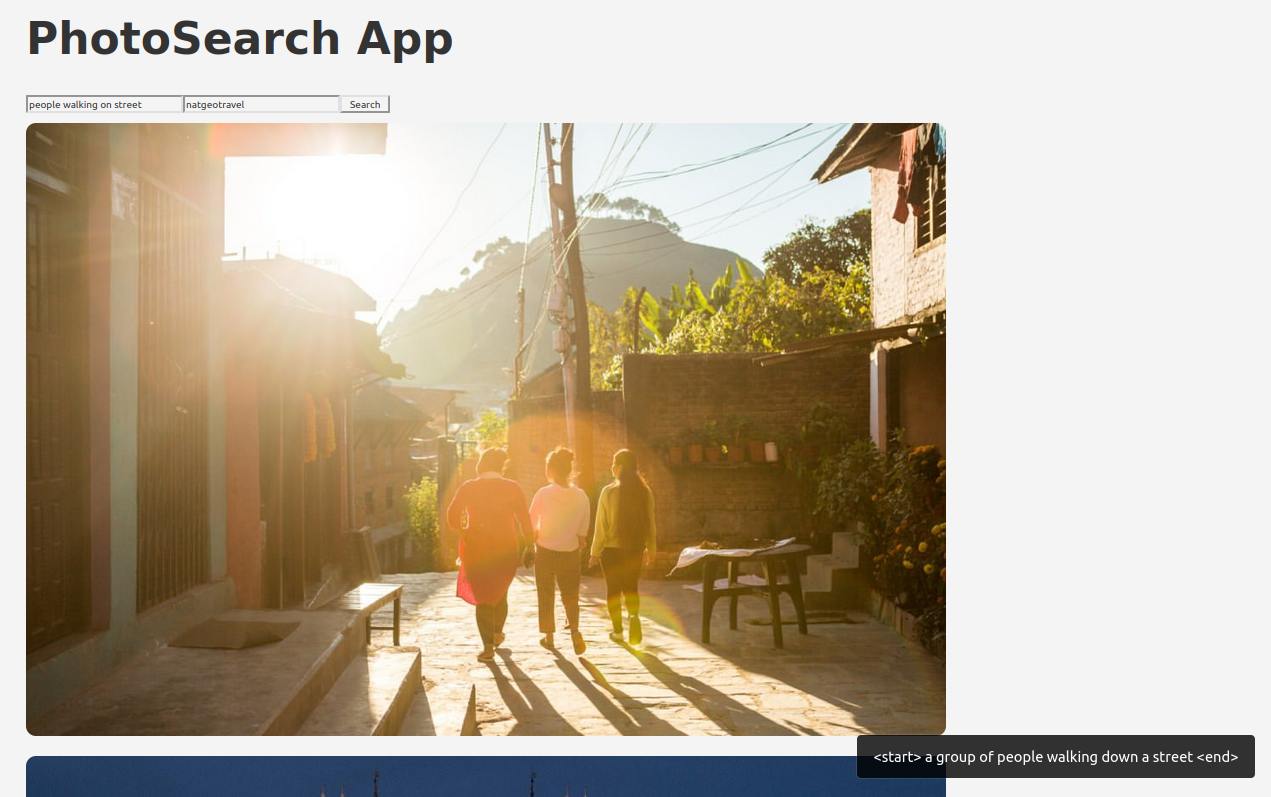
L’application est hébergée ici : https://photosearch-app.netlify.app/. Lors du lancement de la première requète, il est possible que la réponse soit assez longue, le temps du redémarrage du serveur. N’hésitez pas à la tester !