Q-Learning : Apprendre (tout seul) les règles du jeu
Je me suis toujours demandé comment les intelligences artificielles fonctionnaient dans les jeux vidéos. Comment les ennemis d’un jeu savent comment attaquer, éviter, fuir le joueur selon le contexte ?
En fait, dans la plupart des jeux, le comportement des IA est codé par une simple liste de conditions : à l’avance, les concepteurs déterminent une liste d’états du jeu, et, pour chacun de ces états, un ensemble d’actions à exécuter. Dans un jeu simple comme Pacman, ça pourrait par exemple ressembler à ça :
 Deux états, deux actions.
Deux états, deux actions.
Cette manière de programmer l’IA, appelée Finite State Machine, est une méthode simple permettant de créer des agents s’adaptant à leur environnement. Essayons par exemple d’écrire le programme pour l’IA d’un jeu de morpion :
| Etat | Action |
|---|---|
| La case centrale est libre | Jouer dans la case centrale |
| Une case latérale est libre | Jouer dans la case latérale |
| L’adversaire a deux pions alignés | Le bloquer |
| J’ai deux pions alignés | Compléter la ligne |
A chaque tour de la partie, notre programme observera donc l’état du jeu et effectuera l’action correspondante.
C’est une bonne méthode pour coder des agents s’adaptant au comportement de l’adversaire. Par contre, elle nécessite de réfléchir en amont à cette liste d’états et d’actions. Cela implique d’avoir déjà une bonne connaissance des règles et des stratégies gagnantes du jeu. Et oui, si notre programme se retrouve par malheur dans un cas que l’on avait pas prévu en amont, il sera tout simplement bloqué.
Une manière intéressante de faire serait de faire en sorte que le programme construise, au fur et à mesure de ses parties, sa propre stratégie. En soi, un peu comme ce que font les humains : Lorsque nous jouons pour la première fois à un jeu, nous n’avons pas besoin de connaitre à l’avance et en détail ses stratégies gagnantes. Nous connaissons seulement les règles, et petit à petit, nous apprenons quelles actions sont les plus probables, à chaque étape du jeu, de nous mener à la victoire.
Les bases du fonctionnement
Nous allons essayer de créer un programme apprenant à jouer au morpion par lui même. Essayons d’abord de décrire à quoi pourrait ressembler ce programme.
Lors d’une partie, à chaque étape, le plateau du jeu va être constitué d’une certaine disposition de ronds et de croix, par exemple, celle là :
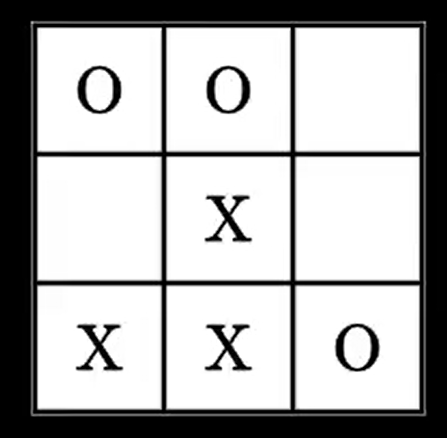
ou celle là :
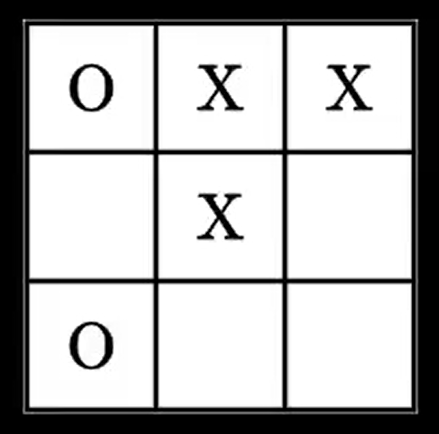
En tout, le joueur peut se retrouver face à 5478 dispositions, ou états différents.
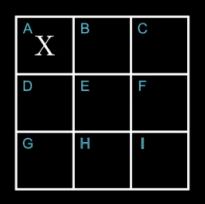
A chaque tour, le programme se retrouvera face à un de ces états, et devra accomplir une action, c’est-à-dire jouer quelque part. Le plateau du jeu étant constitué de 9 cases, il y a au plus 9 actions possibles, qu’on peut labelliser de A à I :
On va donner à notre programme un but à atteindre : Maximiser un nombre de points au cours de ses parties. Pour chaque partie, on lui attribue 1 point lorsqu’il gagne, et -1 point lorsqu’il perd.
Illustrons ce mécanisme par un exemple, dans un état au hasard. Ici, le programme peut jouer en B, F et H.
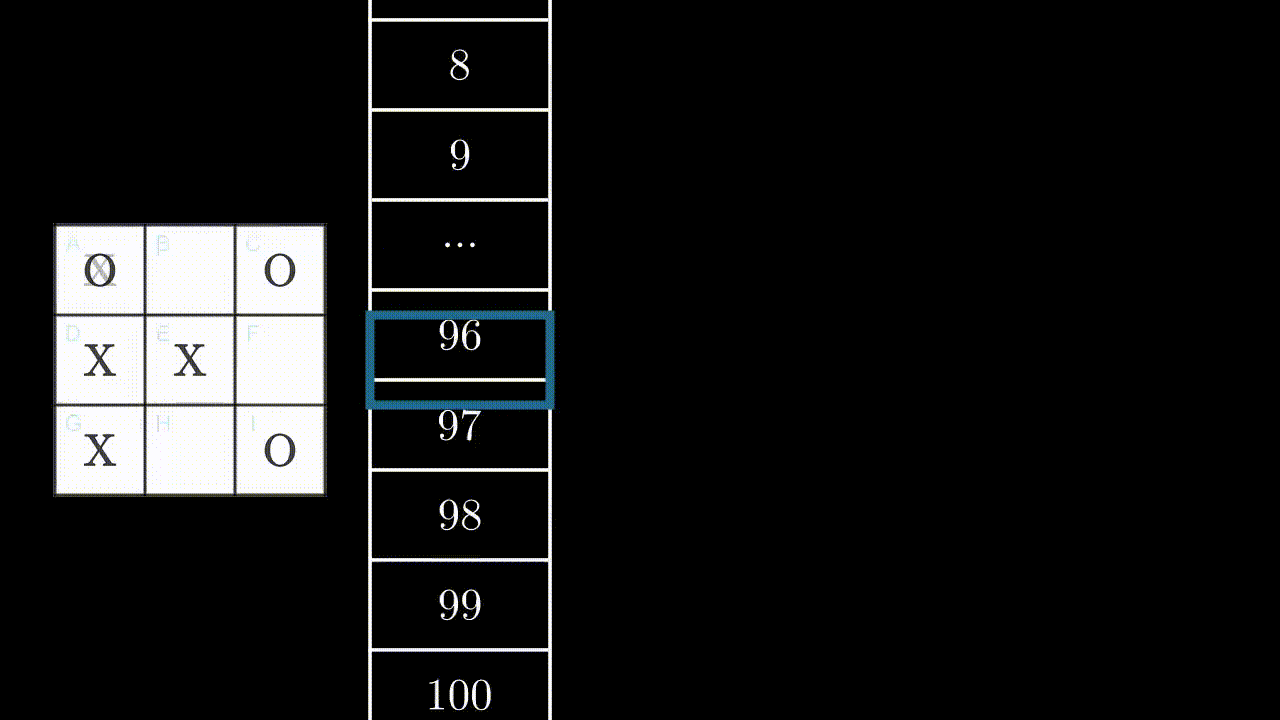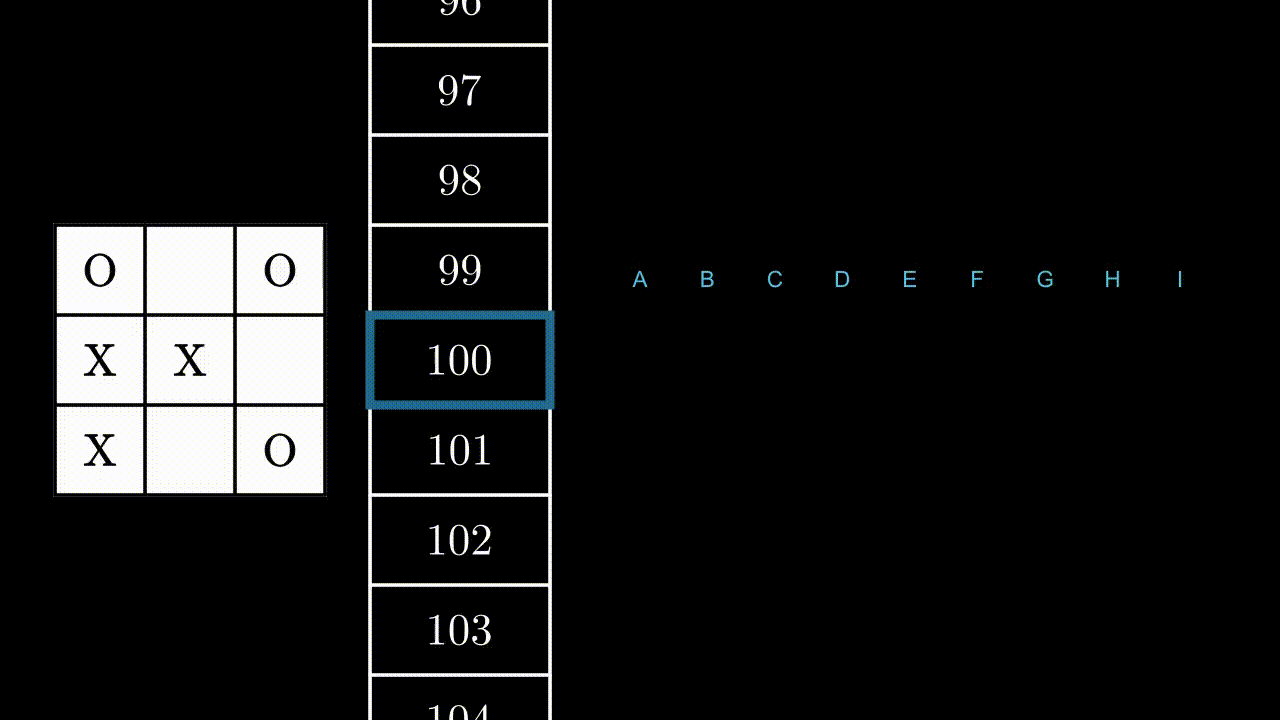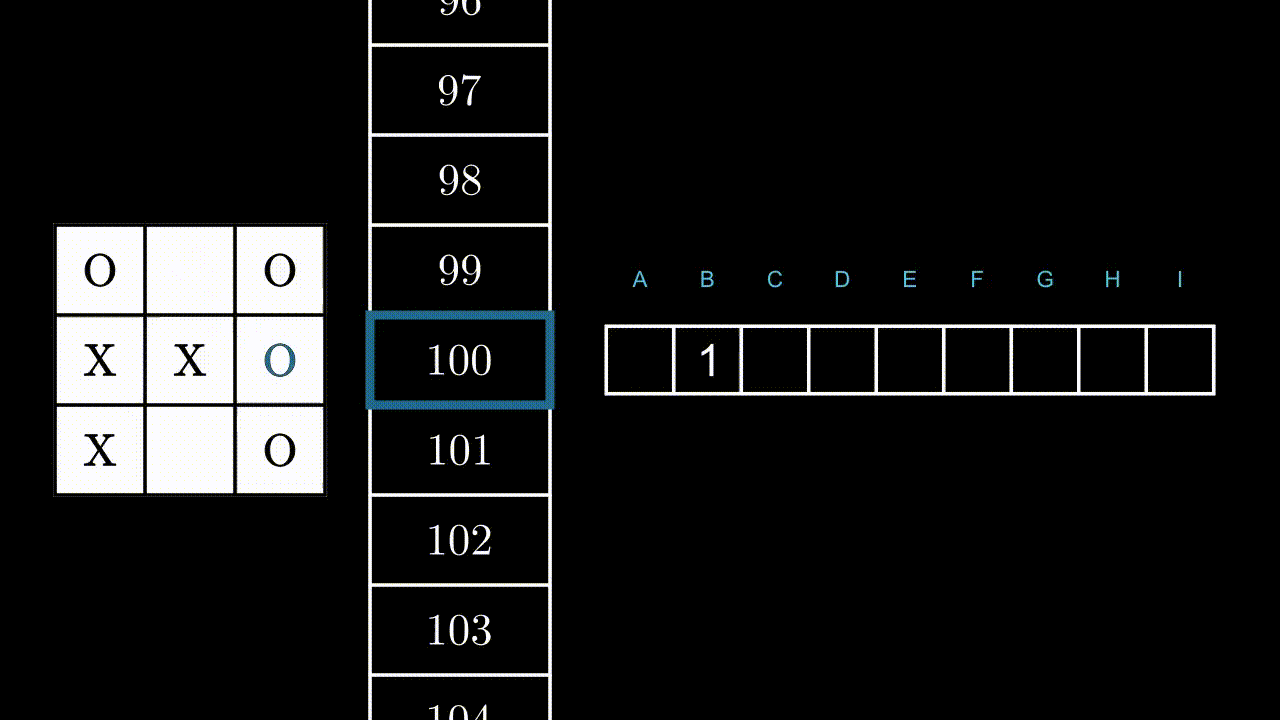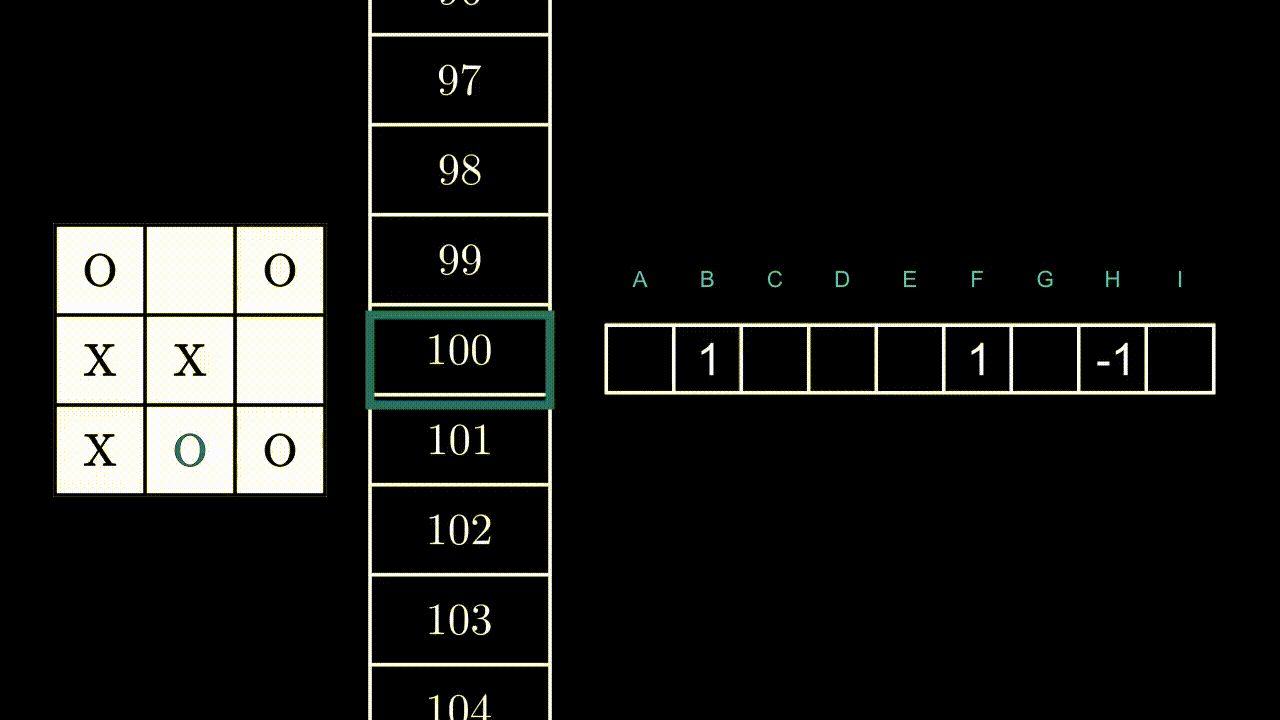 Si le programme joue en B ou F, il gagnera la partie : +1 point pour lui. Si il joue en H, il est très probable que l’adversaire joue en F au prochain coup : -1 point.
Si le programme joue en B ou F, il gagnera la partie : +1 point pour lui. Si il joue en H, il est très probable que l’adversaire joue en F au prochain coup : -1 point.
Imaginons un instant qu’on ait au préalable réussi à évaluer les points que rapportent chacune des 9 actions, dans les 5478 états.
 L’ensemble des points rapportés par les 9 actions possibles, pour chacun des 5478 états.
L’ensemble des points rapportés par les 9 actions possibles, pour chacun des 5478 états.
Si on arrive à évaluer parfaitement combien de point rapportent chaque action dans chaque état, on peut simplement demander au programme de chercher, à chaque fois qu’il rencontre un état, l’action qui lui rapportera le maximum de points, et accomplir cette action :
Action(t) = argmax( Table[Etat(t)] ) Le programme effectue l’action lui rapportant le plus de points probables, selon les valeurs de la table.
Le programme effectue l’action lui rapportant le plus de points probables, selon les valeurs de la table.
Apprendre en se trompant
Mais alors, comment évaluer à l’avant les points que rapportent chaque action, pour chaque état ? On peut tout simplement laisser le programme jouer au hasard, et observer par lui-même les points que lui rapporte chaque action qu’il fait. Au fur et à mesure des ses parties, il gagnera de l’expérience et adaptera son comportement.
Notons R la récompense obtenue après avoir réalisé une action à un état donné. La nouvelle valeur associée à l’état et à l’action en cours sera :
Table[ Etat(t), Action(t)] = R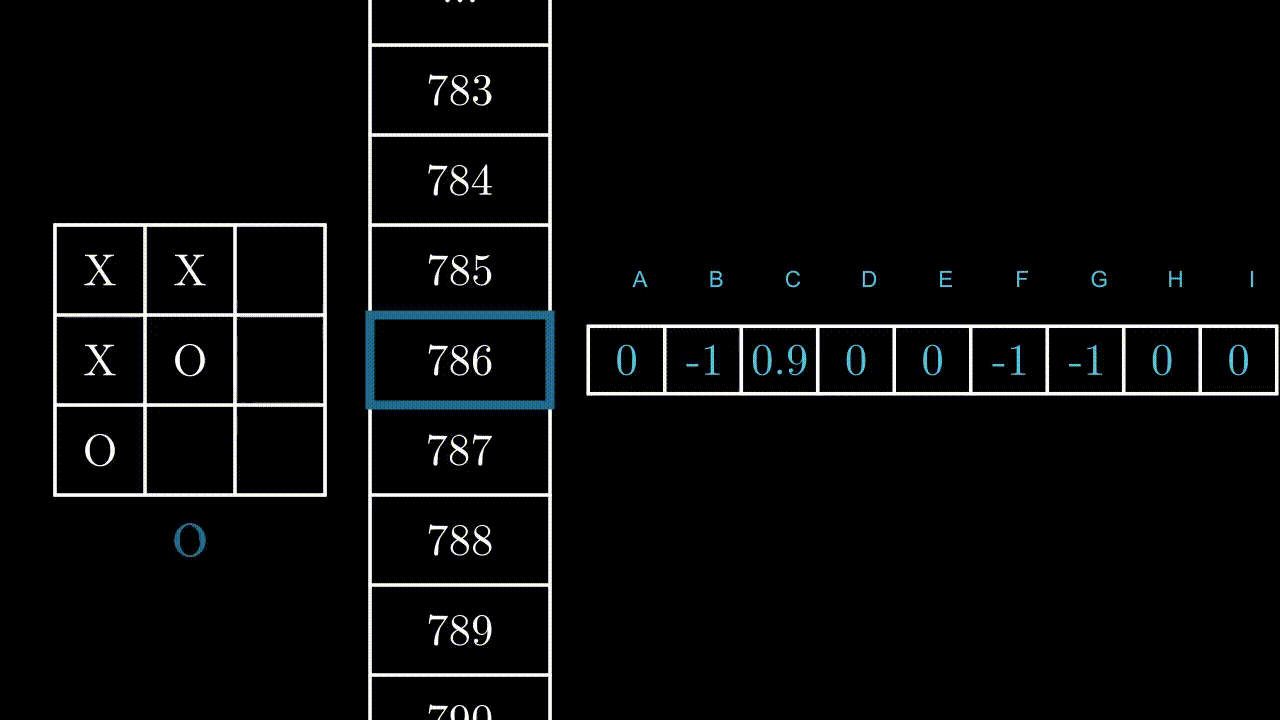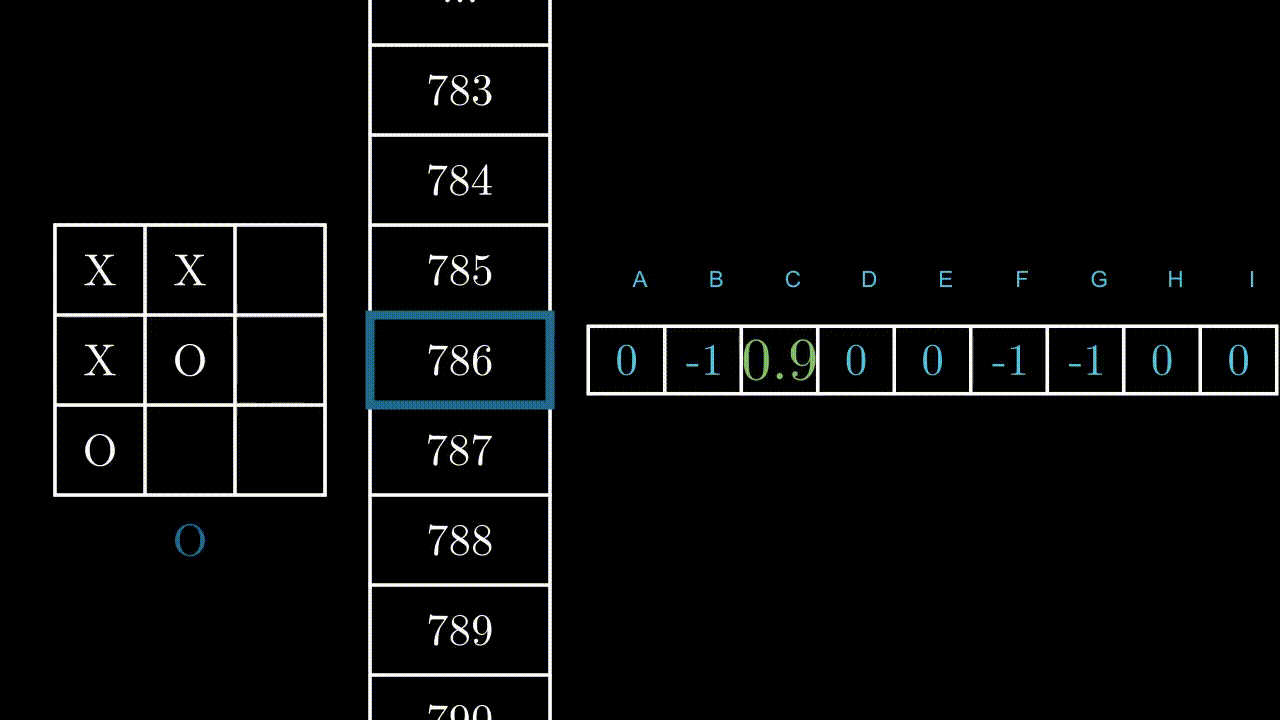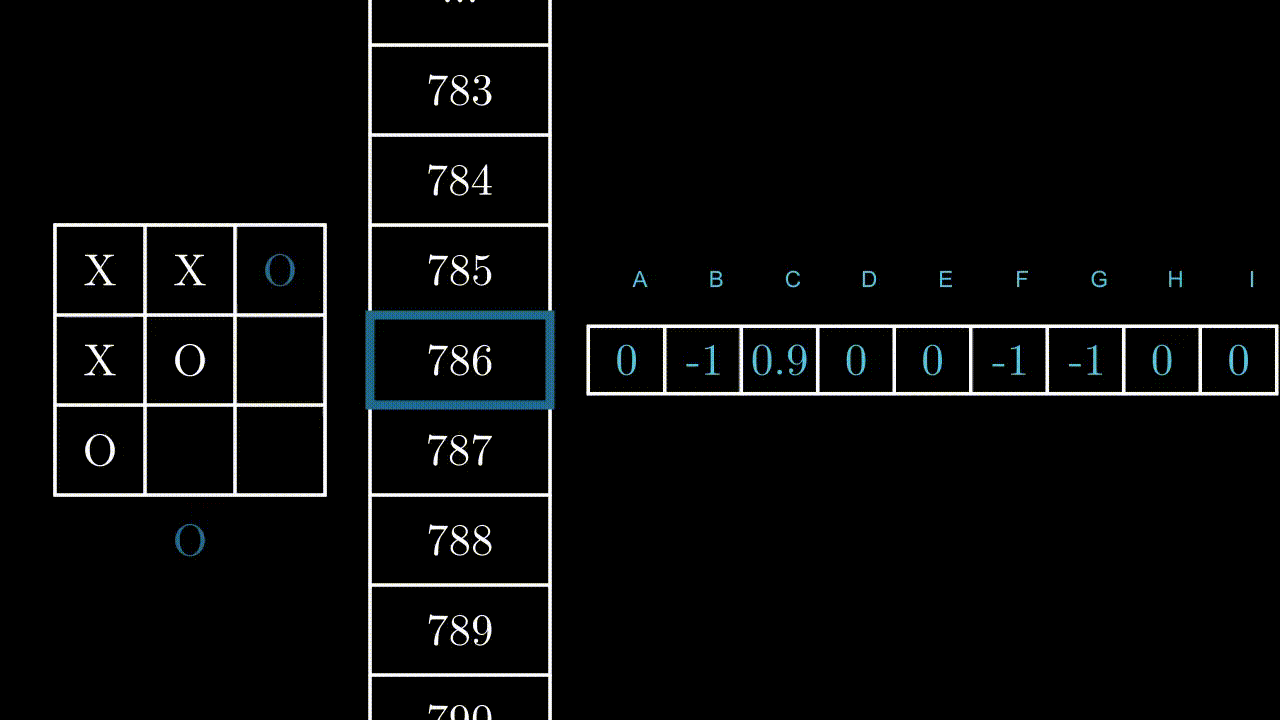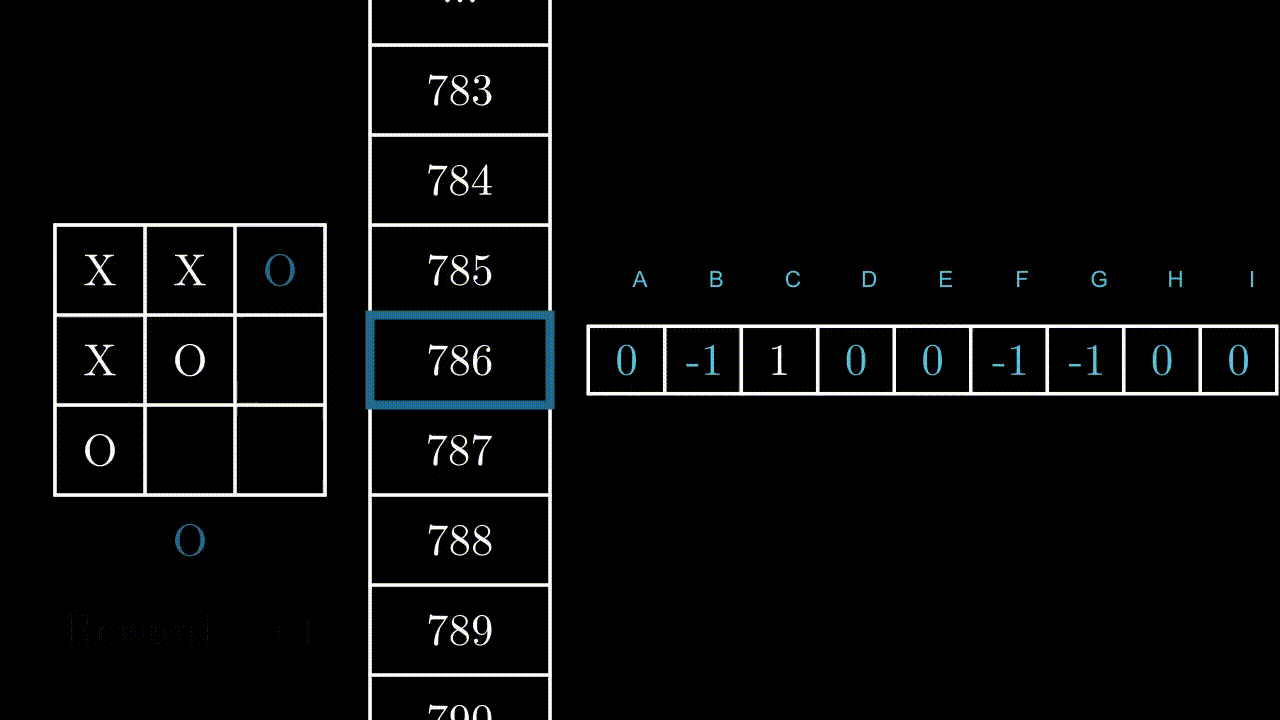 Lorsqu’on reçoit une récompense après une action, on met à jour la valeur correspondante de la table.
Lorsqu’on reçoit une récompense après une action, on met à jour la valeur correspondante de la table.
On remarque tout de même un problème avec notre fonctionnement : toutes les actions du jeu ne rapportent pas de point immédiatement. En effet, au morpion, une partie dure entre 5 et 9 coups, et seule la dernière action rapporte ou fait perdre un point.
En fait, avant chaque action, le programme prend en compte la récompense qu’il aura immédiatement, mais pas celles des tours suivants : il n’a pas de « vision à long terme ». C’est pourtant une capacité fondamentale lorsqu’on veut construire une stratégie sur plusieurs tours.
Pas de stratégie sans vision à long terme
Pour arranger ça, on va faire ne sorte que le programme prenne en compte les récompenses probables qu’il pourrait avoir aux tours suivants :
Lorsqu’il fait une action, le programme va observer la récompense R qu’il obtient immédiatement, mais également évaluer la récompense future R_suivante, évalué comme le maximum des récompenses possibles dans le nouvel état.
R_suivante = max( Table[Etat(t + 1)] )
Table[ Etat(t), Action(t)] = R + R_suivanteDe cette façon, au fur et à mesure des parties, la table sera constituée non seulement des récompenses immédiates de chaque action, mais aussi des récompenses probables plus lointaines.
Mise en pratique
Nous pouvons maintenant faire jouer notre programme et voir comment il se débrouille. Nous allons devoir lui trouver un adversaire : nous pouvons trouver une IA dans n’importe quel jeu de morpion disponible sur Internet. Choisissons-en une et faisons-là jouer contre notre programme.
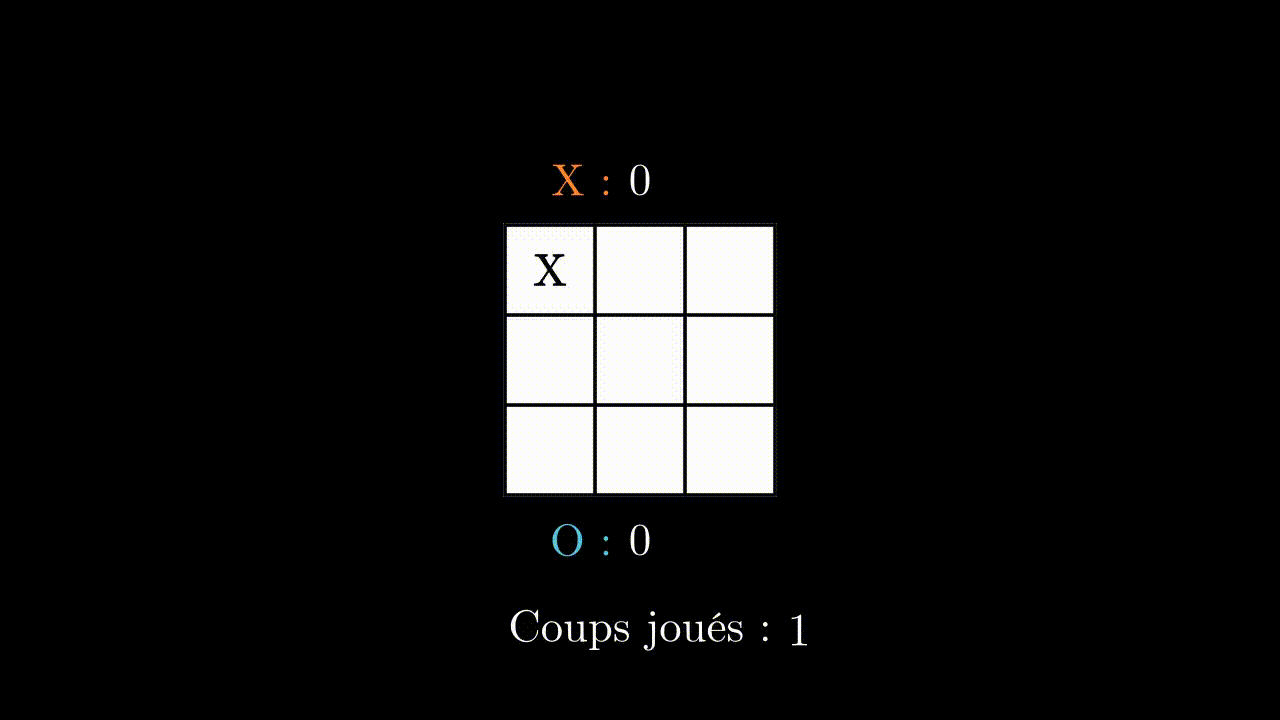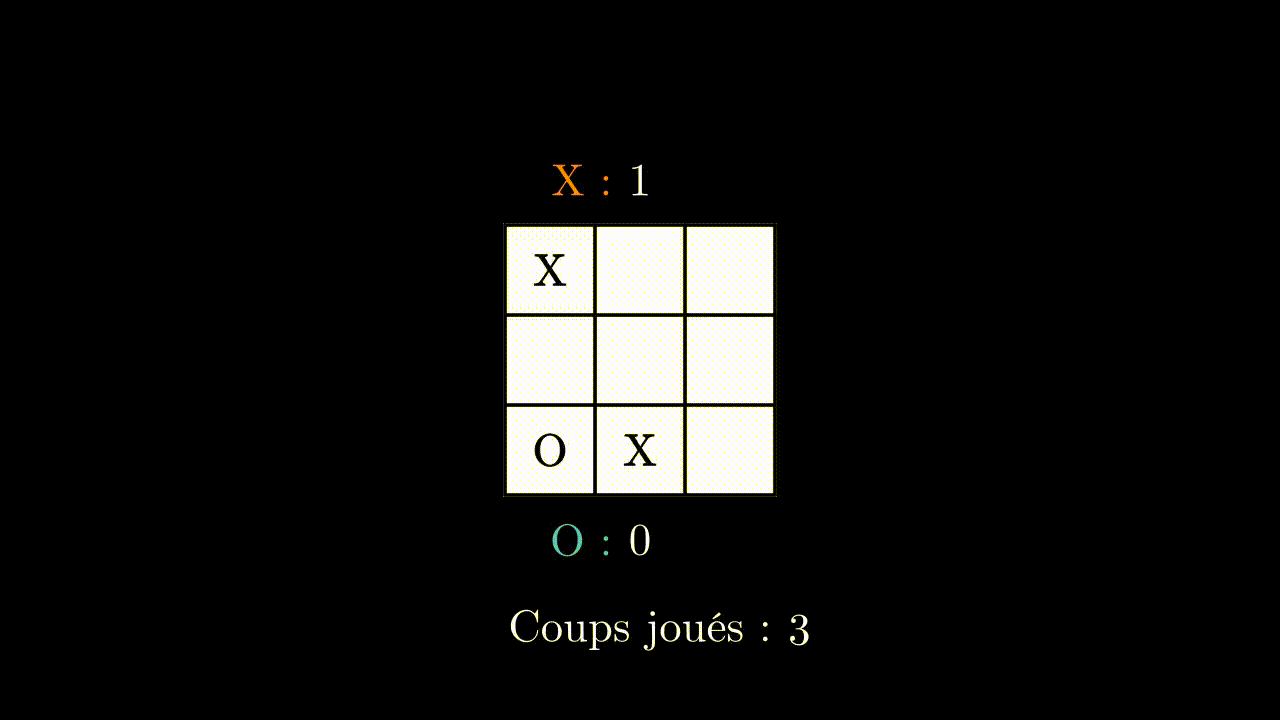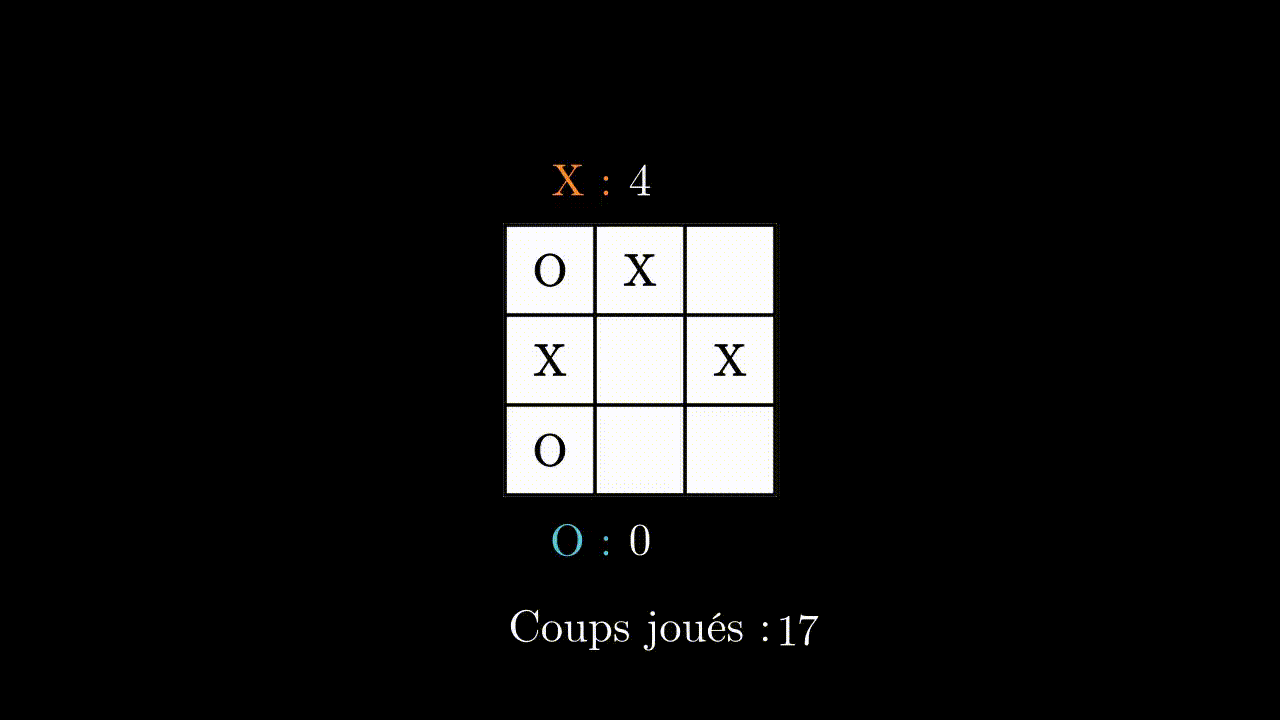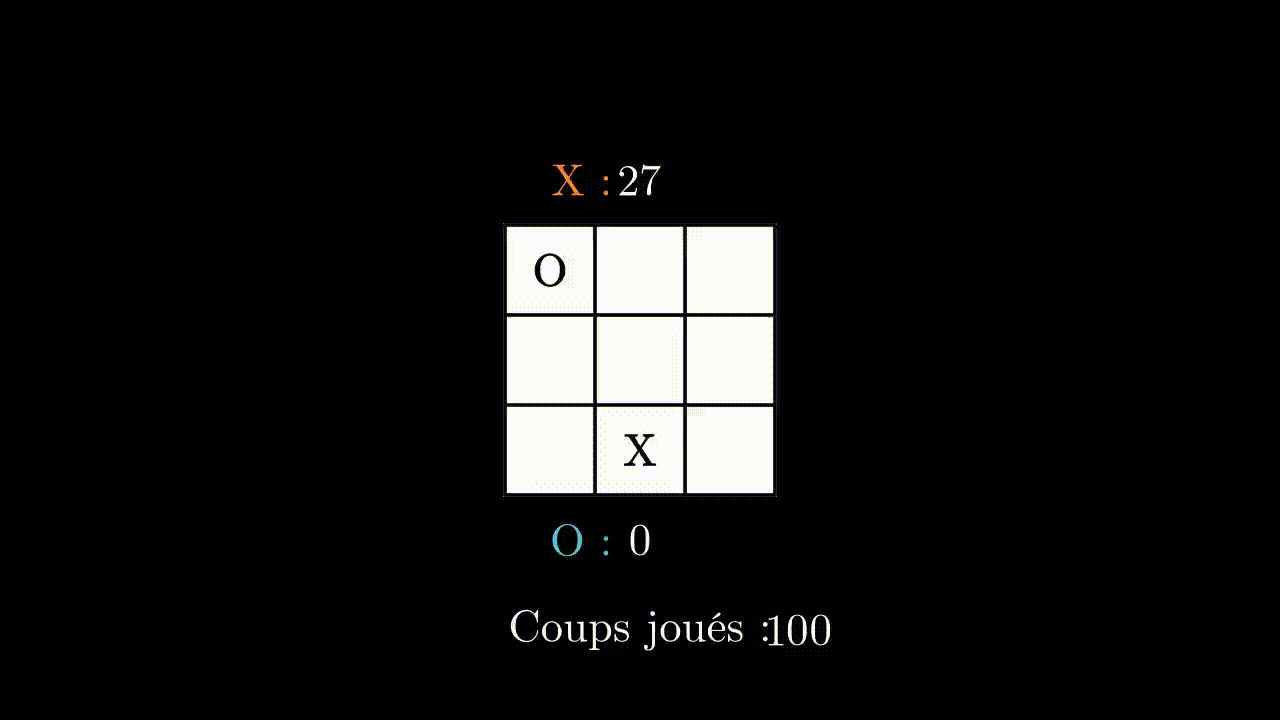
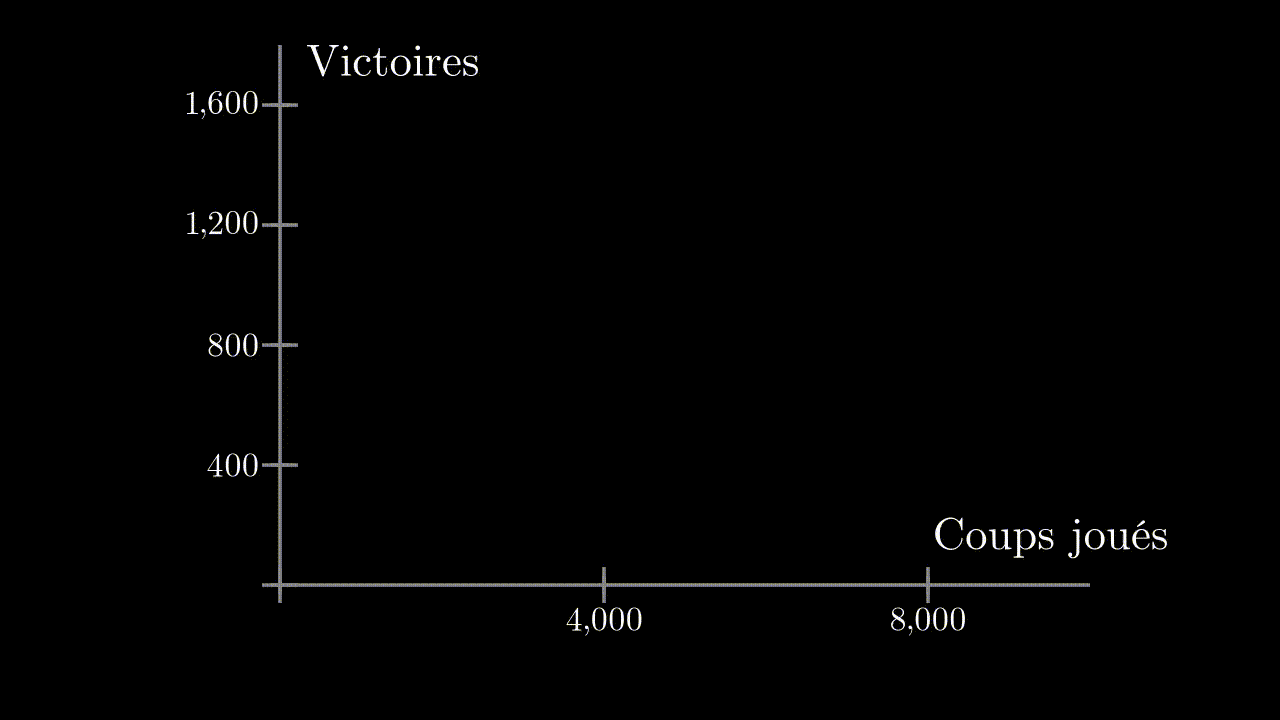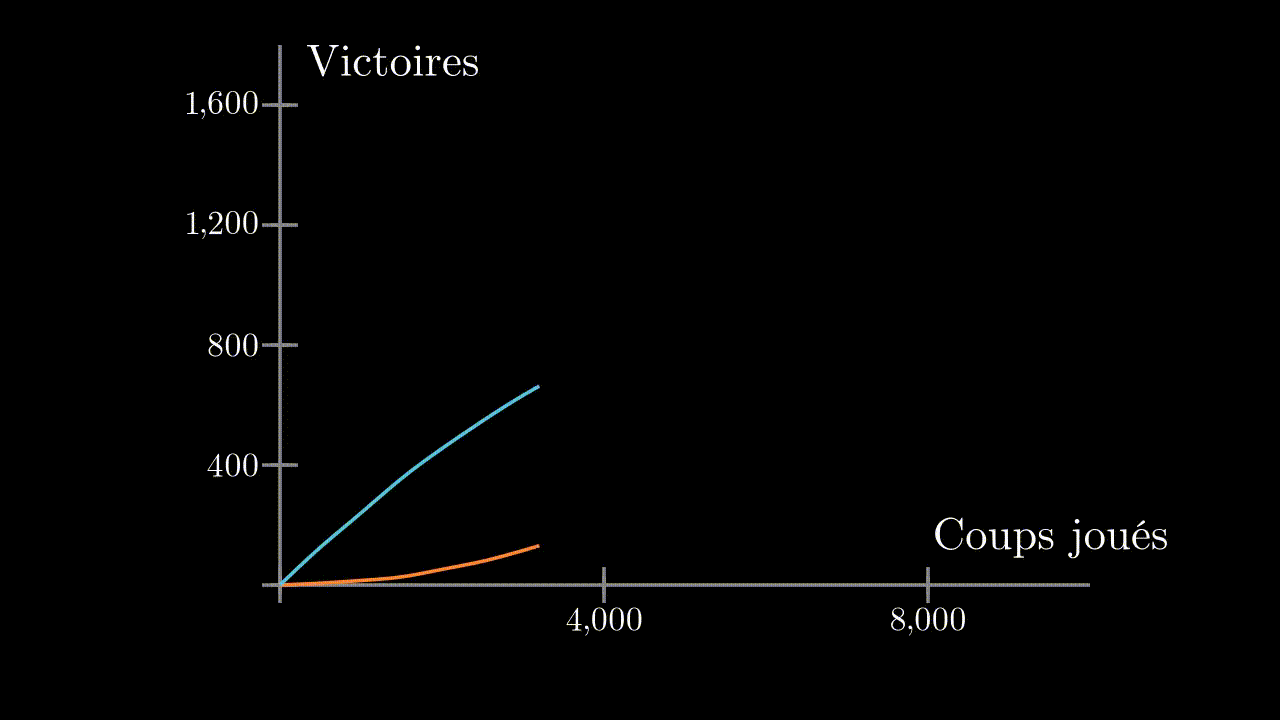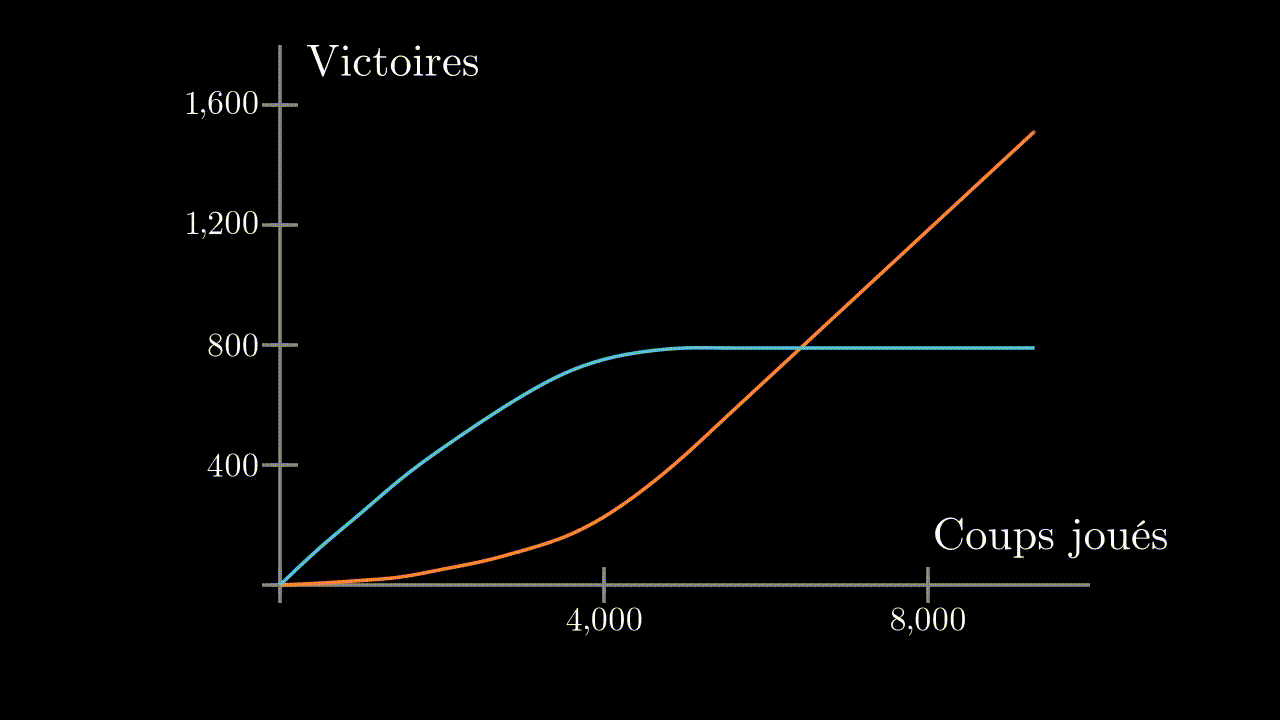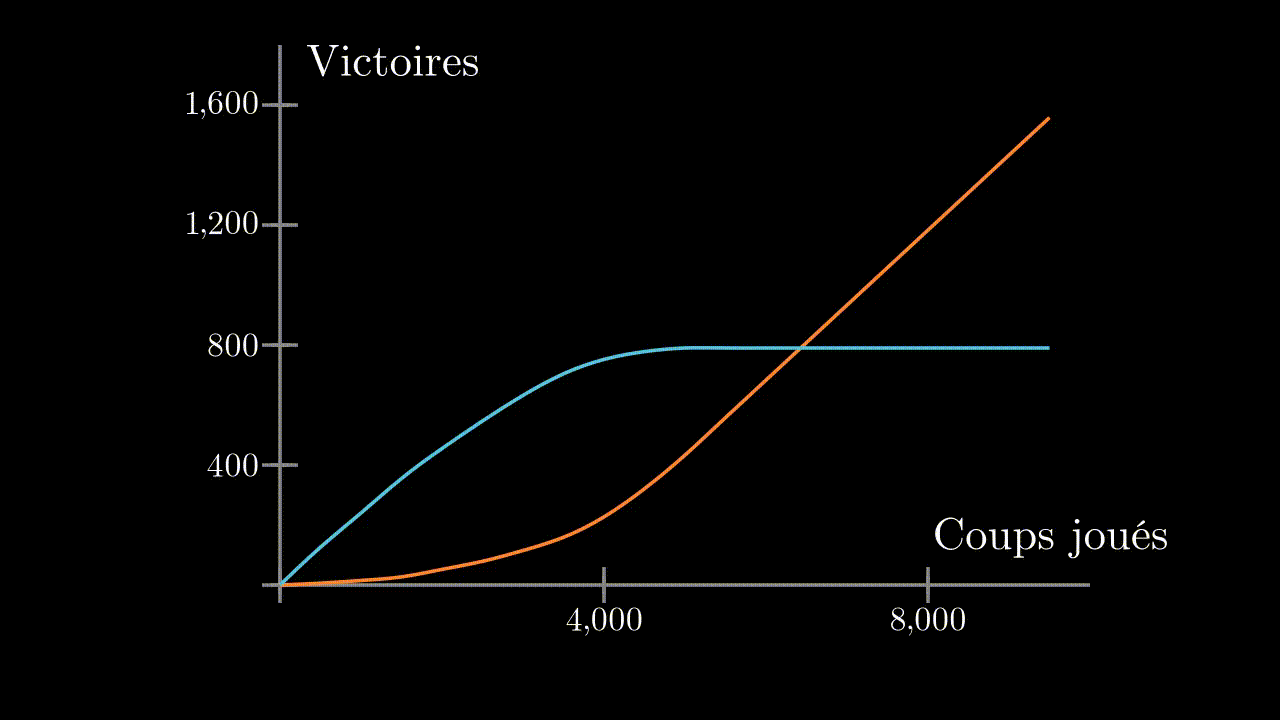
Au début, notre programme se fait systématiquement battre. Mais au bout d’environ 1000 parties, il commence à enchainer les victoires, et finit par ne laisser gagner aucune partie à son adversaire.
Il est donc bien entrainé, et à su trouver une stratégie pour battre son adversaire à tous les coups. Essayons de voir si il arrive à battre un humain ?
Mise en pratique (pour de vrai)
En jouant nous-mêmes contre le programme, surprise : il est vraiment naze. Il ne cherche même pas à nous bloquer, ni à compléter une ligne. Il se fait battre à tous les coups …
Alors, pourquoi ne montre-t-il aucun signe de stratégie alors qu’il s’est si bien débrouillé contre l’IA trouvée sur Internet ?
En réalité, on a mis face à notre programme une IA avec une stratégie unique, codée en Finite State Machine : elle adoptera toujours le même comportement dans une situation donnée. A force de parties, le programme est donc super-entrainé contre la stratégie de l’IA, mais n’est absolument pas entrainé contre un autre adversaire ayant une autre stratégie.
Alors, comment faire pour varier les stratégies rencontrées par notre programme, afin qu’il soie plus fort contre un éventuel nouvel adversaire ? Plusieurs solutions s’offrent à nous :
- On pourrait ajouter, de temps en temps, des mouvements aléatoires lors des parties. Notre programme pourra alors être face à des situations inédites et non inscrites dans la stratégie de l’adversaire ;
- On pourrait également trouver plusieurs IA aux stratégies différentes, et le faire se battre tour à tour contre chacune d’entre elles ;
- Une troisième solution, plus simple, serait tout simplement de créer plusieurs programmes, au fonctionnement identique au premier, et de les faire jouer les uns contre les autres.
La troisième solution est plus simple, et dans un sens plus intéressante : en faisant jouer des programmes qui n’ont à priori aucune connaissance des règles ni des stratégies, on pourrait faire émerger des stratégies nouvelles et efficaces contre un potentiellement efficaces contre un nouvel adversaire.
Nous choisissons de faire jouer 10 agents les uns contre les autres. Et cette fois-ci, effectivement, au bout de 1000 parties, le meilleur agent est capable de concevoir une stratégie contre un joueur humain. Ceci est du au fait qu’il a rencontré un nombre suffisant de stratégie différentes pendant son entrainement.